はじめに
この記事は 食べログアドベントカレンダー2022 の21日目の記事です🎅🎄
こんにちは。食べログシステム本部 技術部 マイクロサービス化チームの栗山です。
マイクロサービス化チームのミッションは「巨大なモノリシックサービスにおける開発の辛さを解消し、少人数のチームが自律的に意思決定しながら開発するためのシステム基盤を作る」というものです。今回紹介する「分散トレーシング」は前回のテックブログ「Debezium Usecases in Tabelog」で紹介した汎用性のある基盤 Change Data Capture とは対極にある、特定の課題に特化したシステム基盤です。そういう基盤ですから導入は特に迷うことなくすんなりいくと思いきや、食べログ規模のシステムに導入するにはまあまあしんどい問題がありました。
食べログに分散トレーシングの導入をはじめたのは2021年の11月のことで、頑張って思い出さないと記事を書けないくらい忘れていましたが、今を逃すともう表に出ることはない気がするので頑張って思い出しました。
なぜ分散トレーシングが必要なのか?
Web アプリケーションのバックエンドを DB から API に切り替えたとき、真っ先に問題になるのはエンドツーエンド監視の難しさでしょう。モノリシックなシステムにおいてアプリケーションサーバの障害と、ユーザが受け取ったエラーの関係は明確です。

しかし分散システムではシステムのどこかで発生した障害が、どのユーザのエラーに対応するのか追跡調査が困難になります。
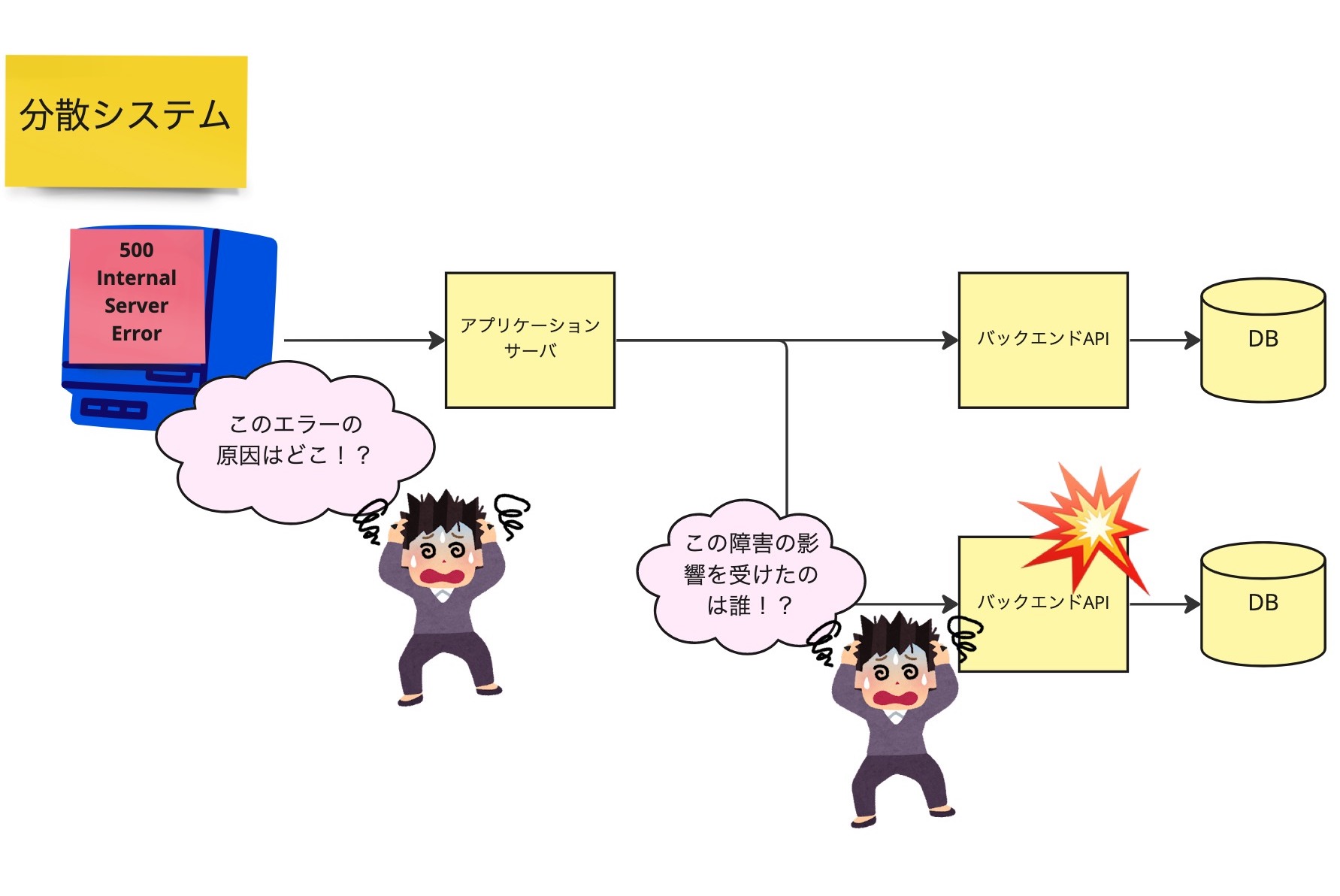
この課題のソリューションが分散トレーシングです。
分散トレーシングの仕組みを大まかに解説すると、各サーバにて計測した処理開始・終了時刻を「スパン」という構造体で出力し、監視バックエンドでスパンを収集して親子関係を紐付けて可視化するというものです。
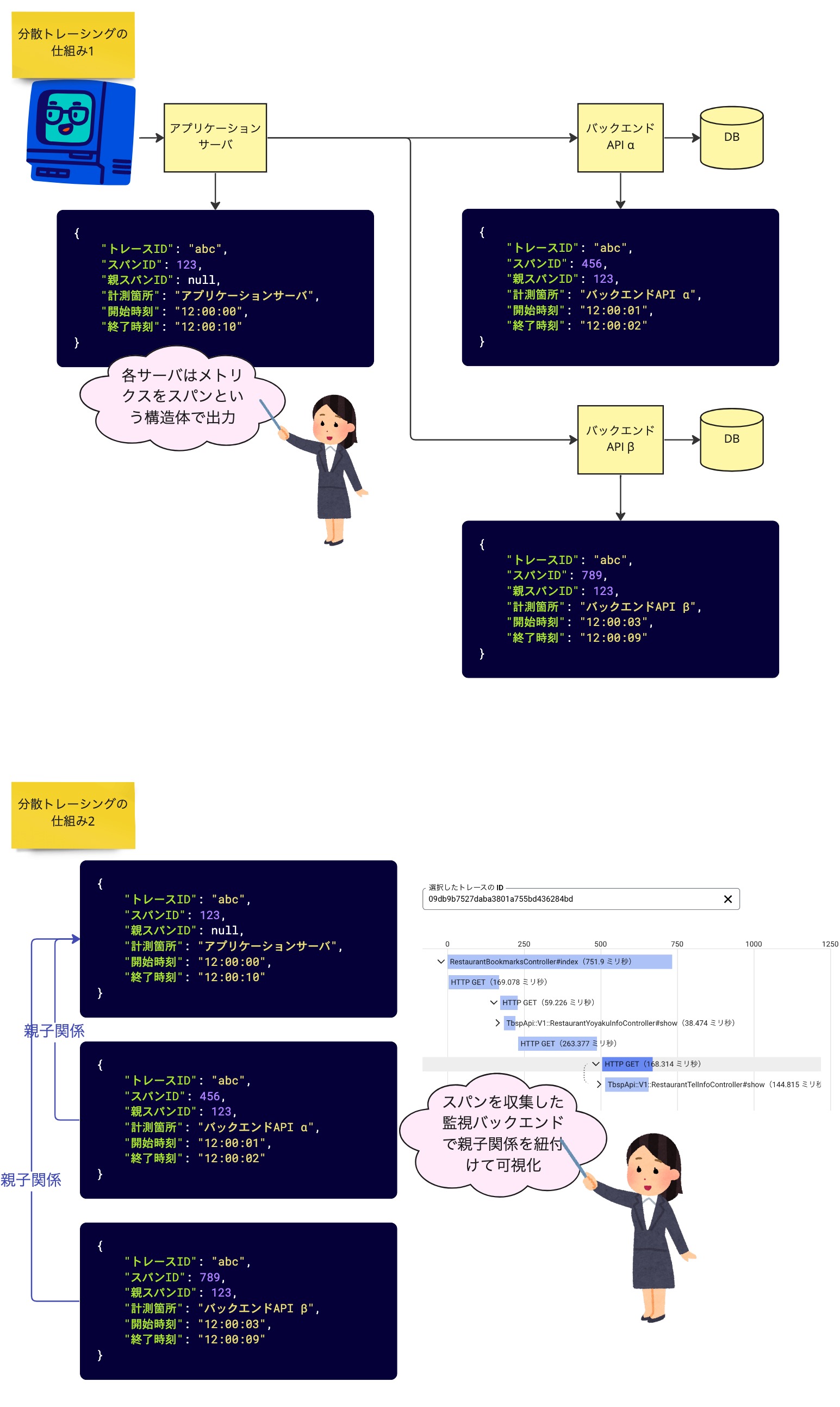
分散トレーシングはマイクロサービスアーキテクチャを採用しているか否かに拘らず、ほとんどの Web サービスにおいて導入するメリットがあると思います。例えば多くのサービスは課金処理を決済代行業者に委託していますから、決済 API でエラーが発生したときにエンドユーザのリクエストと紐付けて可視化できる分散トレーシングが有用なシチュエーションは多々あるでしょう。
分散トレーシングを使用することで、監視中のアプリケーションを通過するリクエストやトランザクションの経過を観察して、アプリケーションのパフォーマンスに影響するボトルネックやバグなどの問題を正確に特定できます。つまり、分散トレーシングはマイクロサービスアーキテクチャの問題である障害発生時の原因究明の複雑化やシステム全体でのパフォーマンスの把握が難しいといったことに対応できる仕組みなのです。
分散トレーシングのプロダクト選定
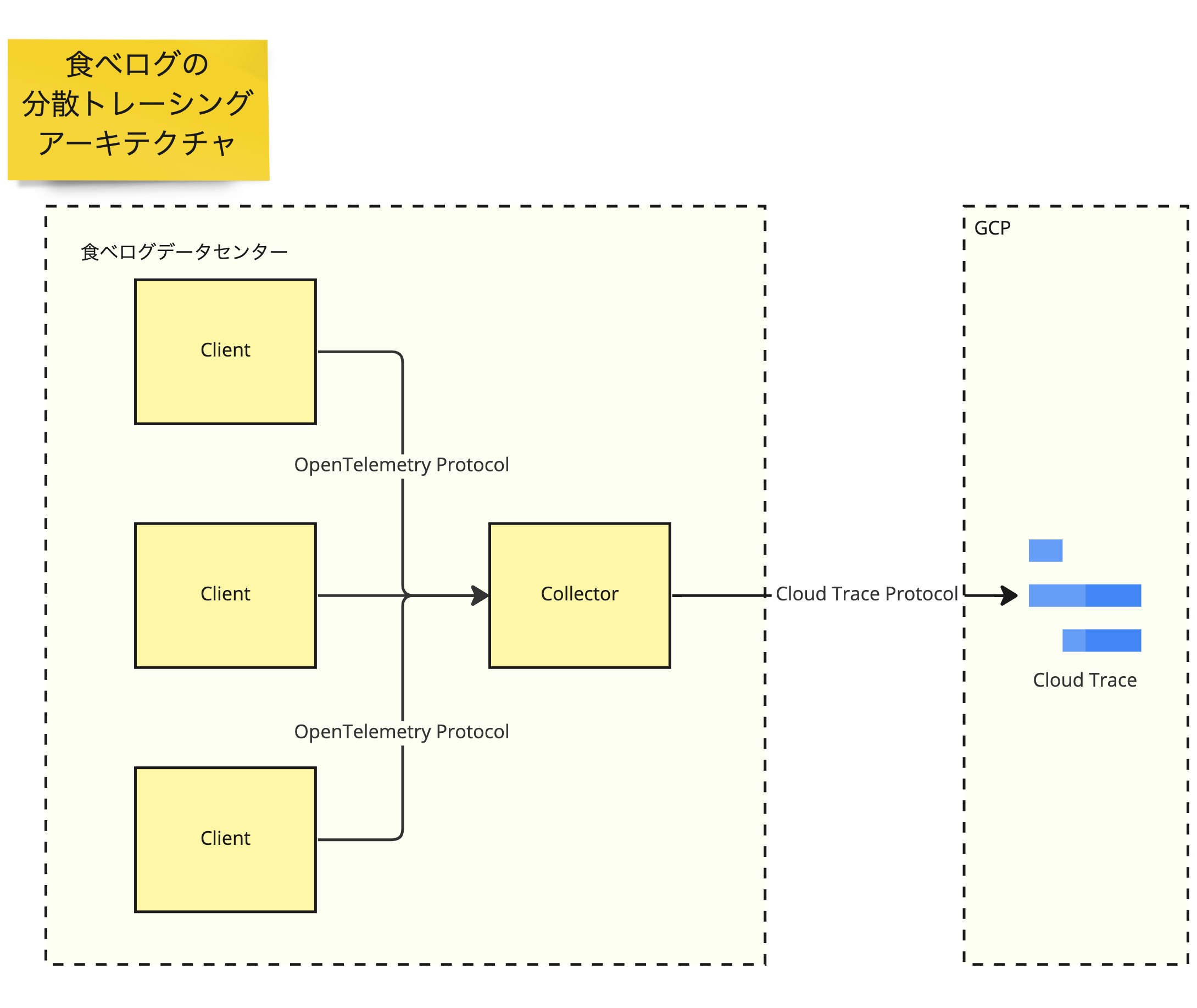
分散トレーシングのプロダクトとして OSS には Zipkin や Jaeger があり、PaaS には GCP の Cloud Trace や AWS X-Ray があり、様々な選択がとれます。食べログでは将来性に加え、柔軟な運用設計といわゆるベンダーロックインのリスクが低減できるプラガブルなアーキテクチャをとれることに着目し、コアプロダクトとして OpenTelemetry を採用しました。
食べログでは Client に OpenTelemetry SDK を導入して、Client から OpenTelemetry プロトコルで Collector というコンポーネントに送信・集約しています。そして Collector から GCP のプロトコルで監視バックエンドである Cloud Trace にエクスポートするアーキテクチャをとっています。
Client が直接ベンダーのプロトコルでバックエンドにスパンを送信するアーキテクチャの場合、ベンダーを乗り換えるときにはシステムの全 Client の SDK を入れ替えるコストがかかります。これはまあまあしんどいです。
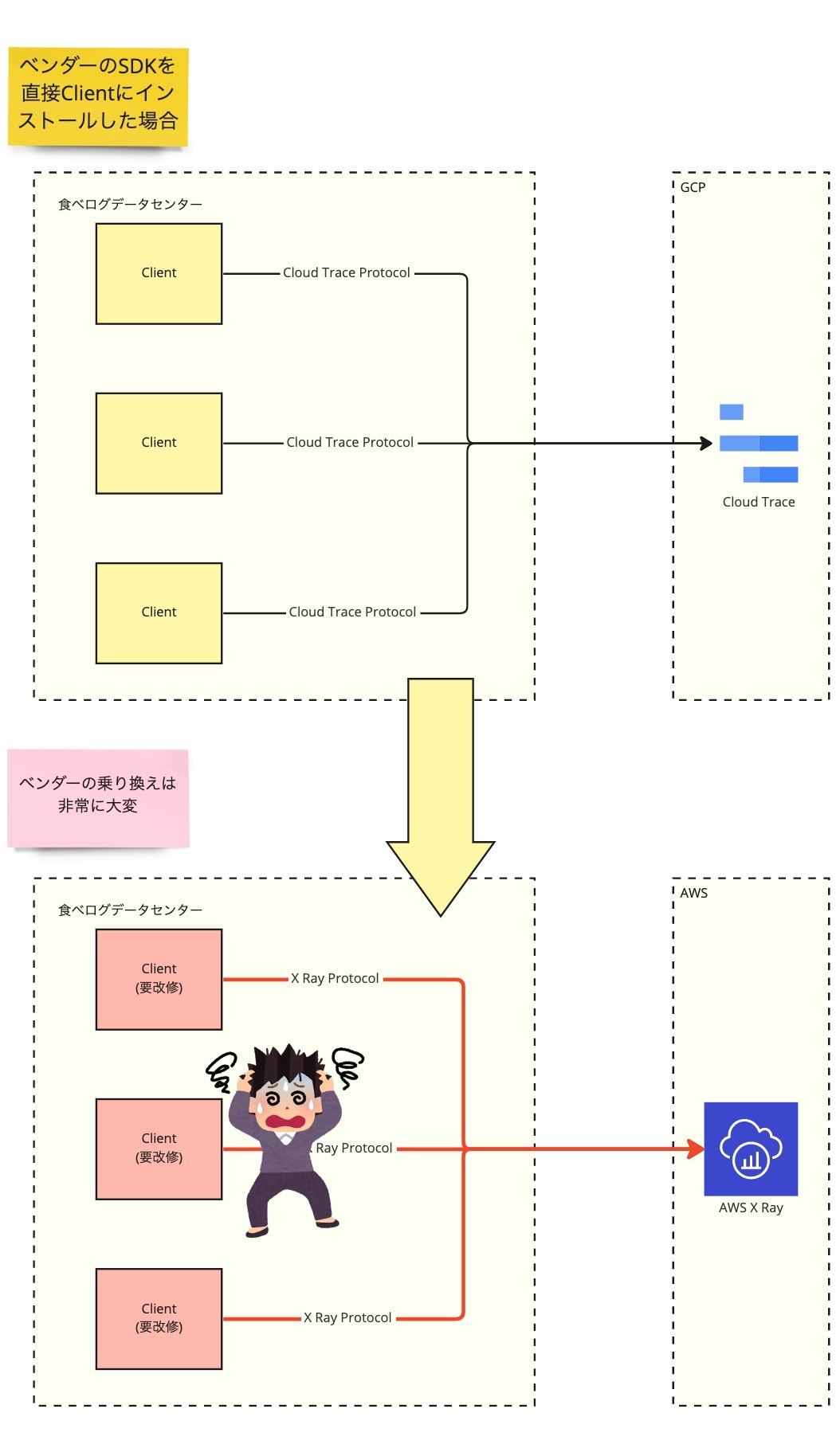
一方食べログで採用したアーキテクチャでは、もしも監視バックエンドを GCP の Cloud Trace から AWS の X-Ray に切り替えたくなったときも、Collector からのエクスポートを X-Ray に切り替えるだけでよいのです。

問題点1: OpenTelemetry の公式サンプラーはサンプリングレートが固定
ここまで紹介してきたように柔軟なアーキテクチャがとれる OpenTelemetry ですが、食べログのサービス規模ではちょっとした問題がありました。
食べログには毎日約 2.5 〜 3.5 億のアクセスがあり、このアクセスを全てトレースするのはコストの面で現実的ではありません。1 Cloud Trace に限らず大抵の分散トレーシングはスパン数に対する従量制課金なので、課金機能のような重要機能は 100 % でサンプリングしても、アクセスの多い検索機能などは低いレートにしてコストを節約したいものです。
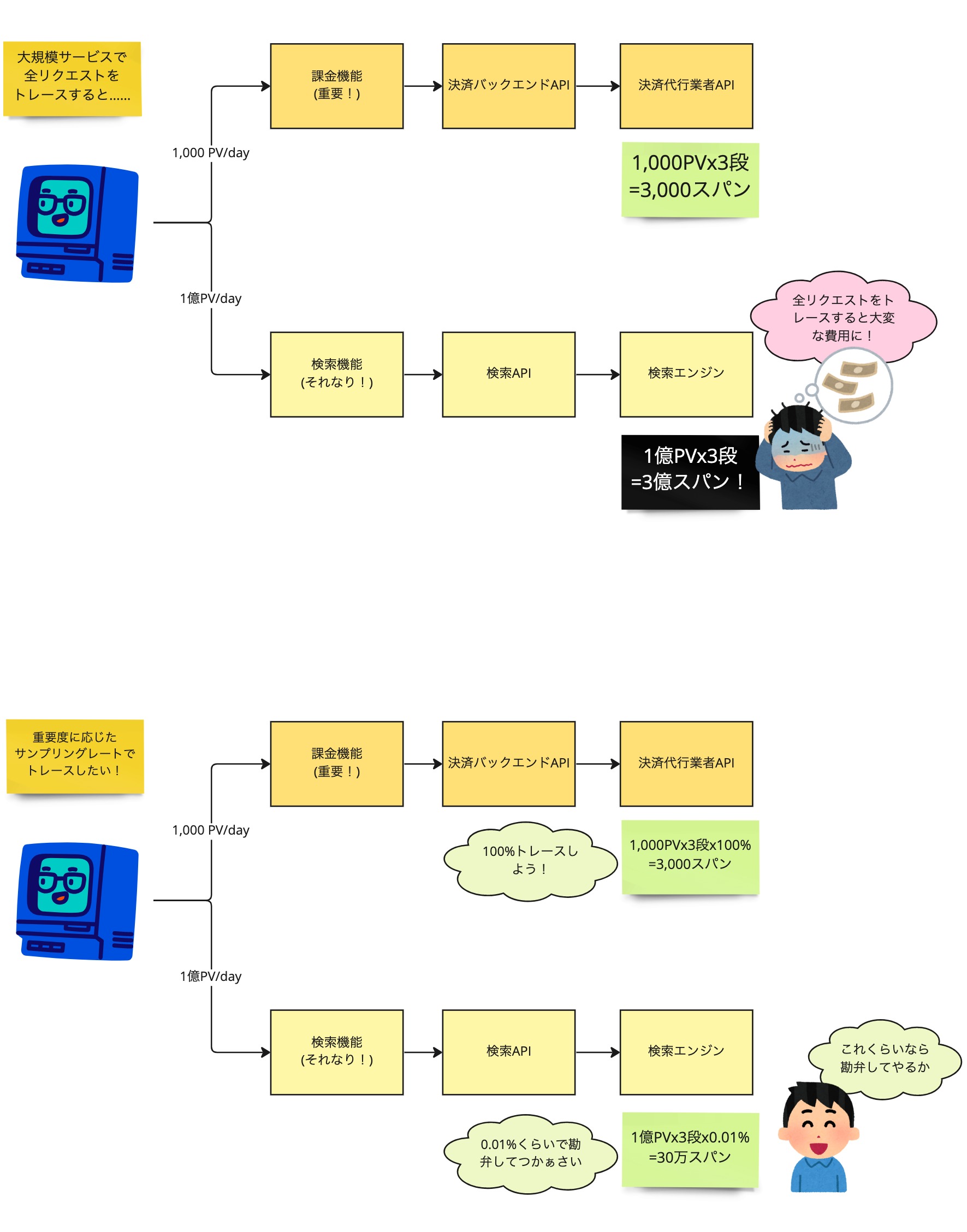
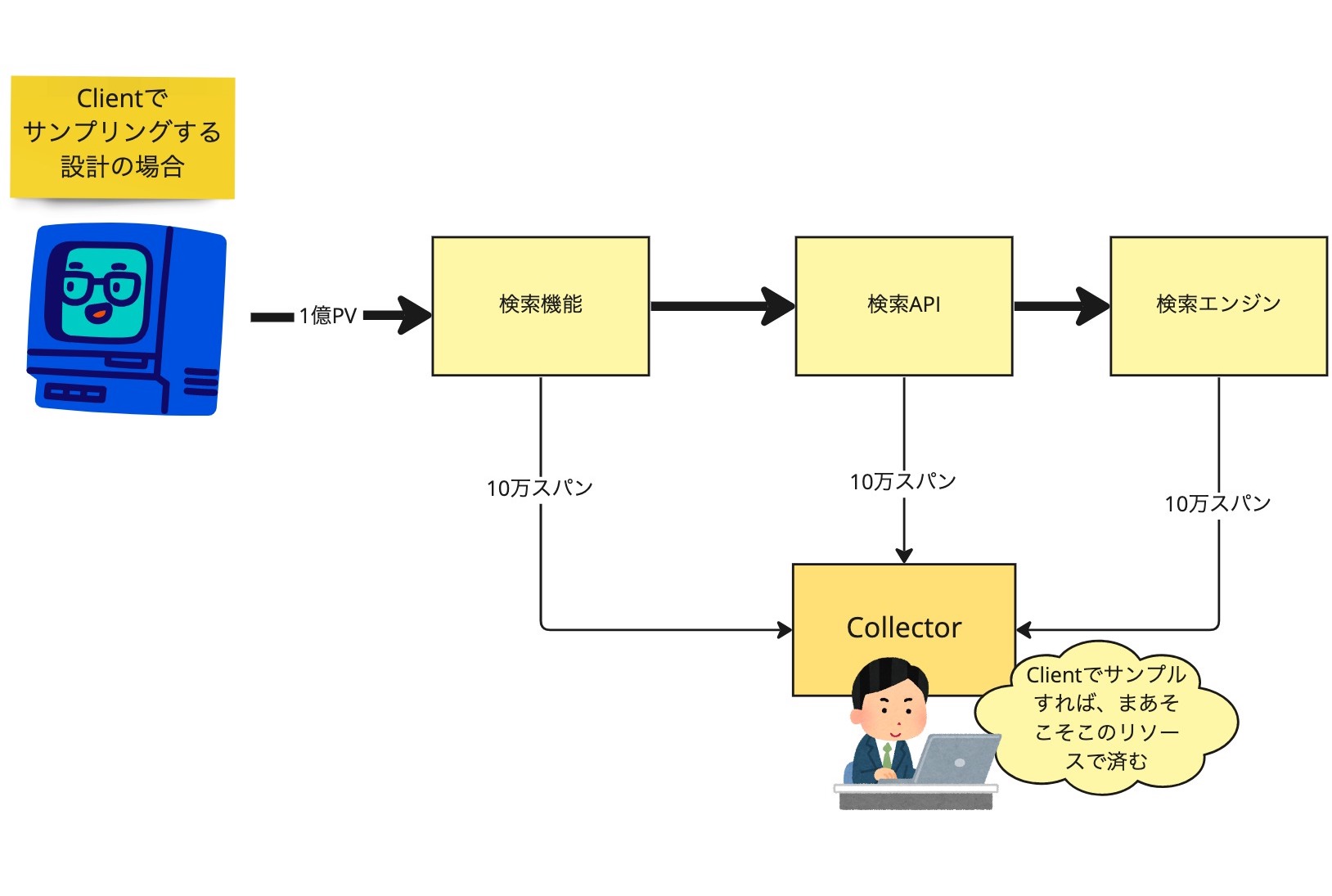
OpenTelemetry 公式の Rails gem には残念ながら1アプリケーションでサンプリングレートを可変にする機能がありませんでした。そこでまずアプリケーションでは 100 % サンプリングして Collector でスパンの内容を見て間引く設計を考えましたが、Collector には大量のデータをさばくためのリソースが必要になり、まあまあしんどいです。 2

そこで食べログでは Rails エンジニアにはお馴染みの before_action によく似た DSL で action ごとにトレースするサンプリングレートを指定できる OtlpPinpointTracer という gem を実装しました。
アプリケーション開発エンジニアはトレースしたい Controller / Action とサンプリングレートを以下のように Rails のコードとして記述するだけで、DevOps 系の構成管理などは不要です。
class SomeController < ApplicationController include OtlpPinpointTracer::DSL trace_action :show, rate: 10 trace_action :index, rate: 0.1 def show # この action は 10 % でトレース end def index # この action は 0.1 % でトレース end end
全ての action を 100 % トレースしたい重要な Controller では以下のように記述します。
class ImportantController < ApplicationController include OtlpPinpointTracer::DSL trace_action rate: 100 def create # 100 % トレース end def destroy # 100 % トレース end end
この DSL は action の前後を挟む callback 処理が実装できる Rails の標準機能 around_action で実装しました。action に入る前にサンプリングする・しないを決め、action の yield を OpenTelemetry SDK の計測ブロックに渡しています。
問題点2: 公式の Active Record 計測実装が他の gem と相性がよくない
もう1つの問題点は公式の Active Record 計測 gem opentelemetry-instrumentation-active_record がモンキーパッチして create などのメソッドをオーバーライドしている点でした。この実装が食べログに以前から導入されているサードパーティー製 gem と相性が悪く公式 gem の導入が困難でした。分散トレーシング導入のためにこの gem の代替実装をするのはまあまあしんどいです。
この課題は Active Record の計測に Active Support Instrumentation を使うことで解決しました。Active Support Instrumentation は Rails 標準の計測機能で、Action Controller や Active Record の処理時間とその他詳細なメトリクスを安全に計測できるインタフェースを提供してくれます。
OpenTelemetry は公式でこの計測手法に対応した gem opentelemetry-instrumentation-active_support を提供しています。しかしこの gem をそのまま導入したところ Cloud Trace 上でスパンが一律で active_record sql と表示され視認性がよくなかったので、食べログでは公式 gem を参考にして Cloud Trace 上でモデルとクエリの発行先 DB クラスタがわかる実装にしました。

まとめ
以上、大規模サービスならではの苦労もありましたが、食べログにとって使い勝手のよい分散トレーシング基盤が実現できました。
- 食べログのようにアクセス数が多いサービスでも、サンプリングレートを柔軟に設定できるようにして、コスト削減と重要機能の重点的なトレースを両立できた
- Rails 標準の監視機能を応用して安全でなおかつ視認性のよい可視化が実現できた
マイクロサービス化チーム・基盤ユニットでは分散トレーシングを障害対応のような「守り」の改善と、パフォーマンスチューニングのような「攻め」の改善の両面で活用すべく展開を進めています。
マイクロサービス化チームで働くことにご興味のある方は、ぜひ採用サイトからご連絡をください! エンジニア組織の文化風土などを面接前に知りたい方は、本採用プロセス前にカジュアルな面談から対応できます。フリーコメント欄に「カジュアル面談希望」とご記載ください。ご応募お待ちしております!

明日は @redpine の「スクラム開発のメリット 〜食べログノートUIUXチームでスクラム開発を初経験して〜」です。お楽しみに!