はじめに
こんにちは。食べログシステム本部 技術部 マイクロサービス化チームの栗山です。
マイクロサービス化チームのミッションは「巨大なモノリシックサービスにおける開発の辛さを解消し、少人数のチームが自律的に意思決定しながら開発するためのシステム基盤を作る」です。2021年の Advent Calendar ではチームの成果として、食べログのレストラン検索インデックス同期システムを Change Data Capture (CDC) プロダクトの Debezium により改善した事例と、1 メッセージング基盤を Apache Kafka にリプレイスした事例を紹介しました。2
マイクロサービス化チームが提供するシステム基盤には例えば分散トレーシングのように特定の課題に特化したものもありますが、中には様々な課題に応用できる基礎技術的なものもあります。Change Data Capture (CDC) は後者にあたり、データベースに加えられた変更をニアリアルタイムで検出してメッセージに変換するという、シンプルながらパワフルで応用の効くシステム基盤です。
CDC は大別するとデータベースのトランザクションログを参照するログベース CDC と、トリガーを使用するトリガーベース CDC の2つがあり、それぞれに利点・欠点があります。3 私の知る CDC プロダクトはすべて信頼性が高く、低レイテンシーという利点を持つログベース CDC で、食べログで採用している Debezium もその一つです。トランザクションログを参照すると言ってもデータベースサーバのファイルシステムにアクセスするのではなく、レプリケーション機能のインタフェースを利用しています。実は Debezium はソースとなるリーダーデータベースからはフォロワーデータベースの1つに見えています。MySQL のアーキテクチャで説明すると Debezium は、フォローワーデータベースのフリをしてリーダーデータベースに加えられた変更をレプリケーションインタフェースから取得し、InnoDB の替わりに Apache Kafka にメッセージを書き込むプロダクトなのです。4

2021年の食べログにおいて Debezium はまだ検索インデックス同期システムのパフォーマンス改善にしか利用されていませんでしたが、2022年10月現在では様々な課題をスマートに解決できるソリューションとして活用されています。本記事では食べログにおける Debezium の活用事例をわかりやすく、ビジネス的課題を切り口に紹介してゆきたいと思います。
事例1: 検索インデックス同期システムのパフォーマンス改善
レストラン検索は食べログの重要機能です。レストランの情報は多数の業務データ用テーブルに正規化されて記録されていますが、検索エンジンの Apache Solr は1店舗につき1行の非正規化されたインデックス用データを必要とします。人気店舗の場合、検索インデックス用データ1行を業務データ数千〜数万レコードから計算して生成しており、これを業務データ更新と同期処理するのは非現実的です。食べログでは業務データから非同期で検索インデックス用データに同期するシステムを運用しています。
この同期システムのパフォーマンスが総合的に悪く、データメンテナンスのための大量更新や、インデックスが大きく変わる仕様変更が困難なことがビジネス的課題としてありました。
旧検索インデックス同期システムと問題点
こちらが旧検索インデックス同期システムの概要図です。このシステムの問題点は図中に爆弾マークで示した位置にあります。

- 同期処理全体が cron バッチで稼働していて、業務データの更新が検索インデックスデータに反映されるまでのレイテンシが大きい
- 業務データ用テーブルの更新タイムスタンプを WHERE 句で指定したクエリで更新を検知していて MySQL の負荷が高いうえに遅い
- 検索インデックス用データの更新処理がシングルプロセスでスループットが低い
現検索インデックス同期システムと改善点
これらの問題があった旧同期システムを Debezium によるニアリアルタイムの差分検知と、更新処理が競合しないように並列化した Kafka Consumer の組み合わせで改善しました。旧同期システムでは全件洗い替えには数日かかりましたが、現インデックス同期システムでは約3時間足らずで可能です。

- Kafka Consumer によるイベント駆動処理で稼働し、業務データから検索インデックスデータへの反映レイテンシが小さい
- Debezium による業務データ用テーブルの差分検知は低負荷かつニアリアルタイム
- Kafka Consumer の特性により競合なしでマルチプロセス処理ができスループットが格段に向上
マルチプロセスでも処理が競合しないのは少し説明が必要だと思います。Kafka Consumer には Apache Kafka の同一パーティションのメッセージをシングルプロセスでシリアルに処理する特徴があります。同一店舗のデータからキャプチャーされたメッセージを同一パーティションに入るようにデータパイプラインを構築することで、複数プロセスから検索インデックス用テーブルの同じ行を更新する競合が起きなくなります。スループットはプロセス数を上げるとほぼ線形に上昇します。
改善点のまとめ
| 旧システム | 現システム | |
|---|---|---|
| 差分検出方法 | 更新タイムスタンプを WHERE 句に指定した SELECT | Debezium |
| 差分検出所要時間 | 80 秒 | ほぼゼロ |
| 処理プロセス | cron バッチ | Kafka Consumer |
| 処理間隔 | 15 分 | ニアリアルタイム (イベント駆動) |
| 全件処理時間 | 144 時間 | 3 時間 |
この改善により気軽に検索インデックスの全件洗い替えができるようになりました。旧システムでは検索インデックスに影響する仕様変更の際には、仕様変更の影響を受ける店舗を事前にリストアップして、更新件数を減らすことで更新時間を短くする努力をしていましたが、現システムでは気にせず全件洗い替えができます。5
このプロジェクトのノンカット版は2021年の Advent Calendar にあります。ご興味ある方はぜひご覧ください。
事例2: 食べログノート 在庫サマリ更新の検証環境
食べログノートは今年リリースした飲食店向けの予約管理台帳です。食べログネット予約はもちろん、電話予約や他社ネット予約、ウォークイン(ご予約無し来店)も全て統合管理できます。6
飲食店にはテーブルやカウンターのように様々なタイプの卓があります。飲食店の詳細な卓データから「12月24日の18:00から2時間2名の予約ができます」という利用客向けのサマリデータに変換するのは結構重い処理です。今後ネット予約がますます一般的になって予約数が増えるとデータ量も増大してゆき、在庫サマリ更新処理には現在の何倍ものデータを処理できるスループットが要求されるようになります。そこで最近この在庫サマリ更新システムを刷新したのですが、その検証環境の構築に Debezium を活用しました。
在庫サマリ更新は食べログでも有数の重要で複雑な機能なので、新システムを並行稼動させて新旧方式でデータを比較し、同一であると確証できてから新方式に切り替えたい要望がありました。しかしこの検証環境のテーブルに一部「本番データベースで INSERT されたレコードをニアリアルタイムでコピーしたい。さらに検証データベースで UPDATE, DELETE もしたい」という複雑な要件のテーブルがあり、MySQL のレプリケーションによる実現は困難でした。
レプリケーションでは要件を実現できない問題点
ニアリアルタイムなデータコピーを MySQL のレプリケーションで実現しようとすると以下の図のような構成になります。

しかしこの構成には図中に爆弾マークで示した位置に問題があり、実際には要件の半分も実現できません。

- 本番データベースで DELETE したレコードは検証データベースでも削除されて検証中の機能が参照できない
- 検証データベースで UPDATE, DELETE すると、同じ id のレコードが本番データベースで UPDATE, DELETE されたときデータ不整合を検知してレプリケーションが停止する
Debezium + Kafka Consumer による要件の実現
この課題解決はかなり難航して、開発チームでは運用中のアプリケーションを一時的に修正して本番データベースと検証データベースの両方にデータを INSERT する設計も検討されました。しかし本番データベースに加えられた更新を Debezium で検出して、INSERT に対応するメッセージのみ検証データベースにコピーするアイディアを思いつき、要件をアプリケーションからは完全に独立したシステム基盤として実現できました。

- 本番データベースから INSERT だけ選択的に検証データベースに反映できる。本番データベースで DELETE されても問題ない
- 検証データベースで自由にレコードの UPDATE, DELETE ができる。レプリケーションではないのでデータ不整合で停止することはない
改善点のまとめ
| レプリケーション | Debezium + Kafka Consumer | |
|---|---|---|
| 反映レスポンス | ニアリアルタイム | ニアリアルタイム |
| 更新の取捨選択 | 不可能 | 可能 |
| 検証データベースでの更新 | 現実的ではない | 可能 |
なお今回は PoC の時間がとれなかったため検証データベースへの INSERT は Kafka Consumer で実装しましたが、おそらく汎用的なデータベース更新プロダクトの Kafka Connect JDBC Connector と Kafka Connect のメッセージフィルター機能を組み合わせて、設定コードの記述だけで実現できると思われます。7
事例3: 食べログノート サイトコントローラ連携におけるデータ一貫性の保証
前述の食べログノートは、食べログ以外の飲食店向け予約サービスと在庫データの連携ができる、サイトコントローラというサービスと公式に連携できるようになりました。飲食店の予約はシステム的にはシンプルに早いもの勝ちです。サイトコントローラから予約を受け付けて配席し、予約成否のレスポンスを返す処理は重たいので非同期にしたいのですが、受け付けた順序通りに処理する必要があります。従来型の非同期処理では実現が困難です。また途中で障害が発生したときのリトライを考慮すると問題は更に複雑になります。
従来型のメッセージング・非同期処理の問題

- 並列処理の順番が保証できない。サイトコントローラから同一店舗の予約が連続して提携された時に、後から来た予約が勝ってしまうリスクがある
- データベース更新とメッセージ発行の間で障害が発生したとき一貫性が取れないリスクがある。アプリケーションでリトライを考慮してもプロセスの異常終了などは対処できない
2番の問題に対応しうる設計パターンとしては Command Query Responsibility Segregation (CQRS)8 がありますが、従来型の非同期処理から設計を大きく変えることになり、かなりの工数を要します。この件について開発エンジニアからマイクロサービス化チームに相談された時点で、設計と並行して実装が進んでいたので、CQRS パターンを適用するような大きな設計変更はリリースの遅延を招くことが確実でした。
Transactional outbox パターンによる解決
そこでサイトコントローラ連携では Debezium を利用して、以下の図の設計でこの問題に対処しました。アプリケーションは元の設計から大きく変えない上に非同期処理をトリガーするメッセージ発行自体が不要になり、障害発生時のリトライを考慮する必要がないシンプルな実装になりました。
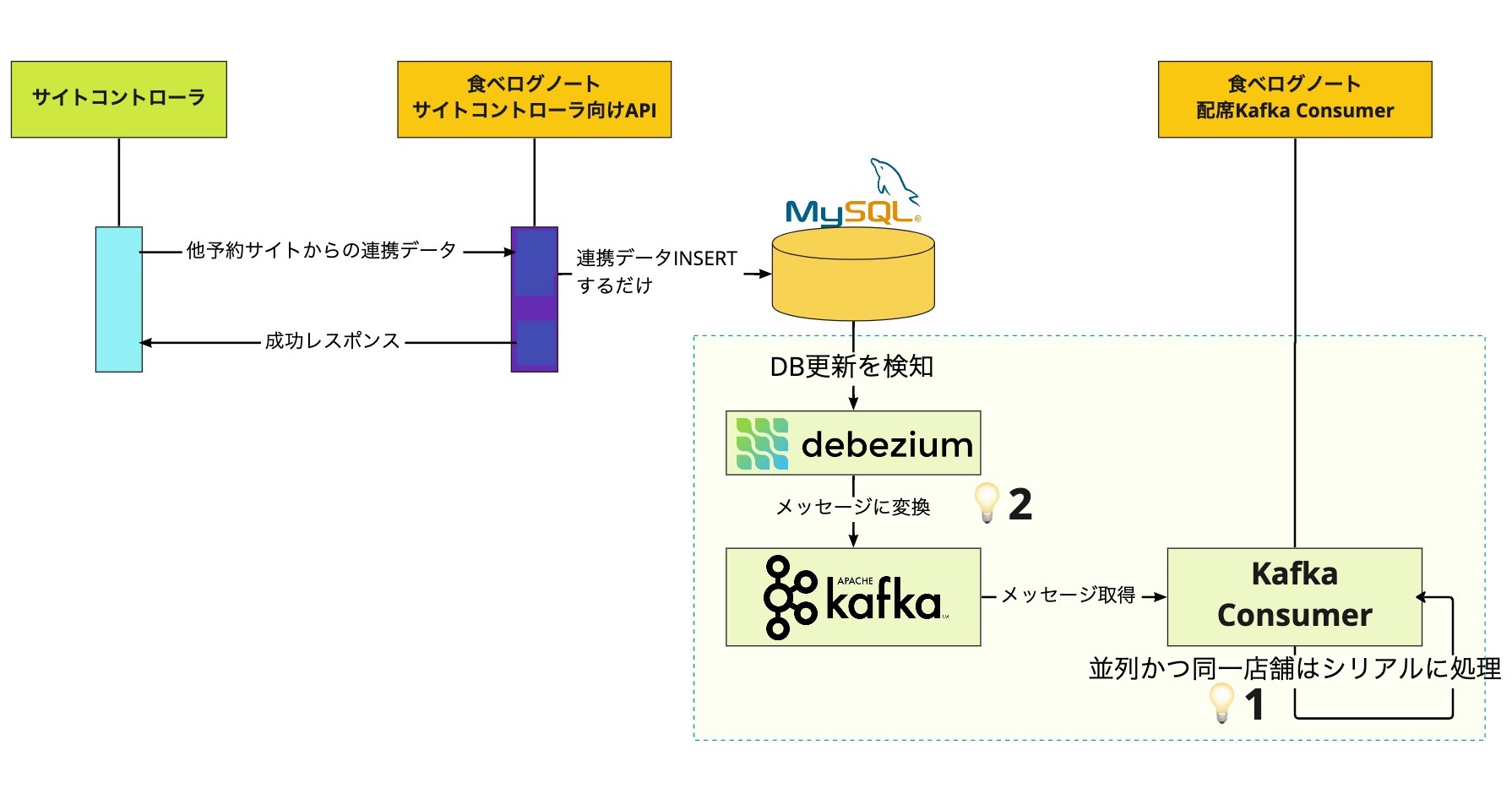
- Kafka Consumer により同一店舗の順序を保証した並列処理を実現
- Debezium によりデータベース更新と Apache Kafka メッセージ発行の一貫性を実現
この設計パターンは一から考えた訳ではなく、マイクロサービス・アーキテクチャにおいて Transactional outbox パターンとして知られています。9 マイクロサービス化チームでは本件のような課題が生じたときにソリューションとして提供できるよう、予め設計パターンの実現方法を調査していました。
改善点のまとめ
| 従来型のメッセージング処理 | Debezium + Kafka Consumer | |
|---|---|---|
| 順序の一貫性 | 保証できない | 同一店舗において保証できる (後述) |
| データベース更新とメッセージ発行 | トランザクショナルではない | トランザクショナル |
Debezium + Apache Kafka で実現できる順序保証は、過剰に受け取られないように詳細な説明が必要だと思います。 事例1で解説したように Kafka Consumer による並列処理は Kafka の同一パーティションについて、シングルプロセスでシリアルに実行されます。このプロジェクトでは Kafka Connect の Single Message Transforms (SMTs) という機能を用いて Debezium から Apache Kafka にメッセージを発行する時点で店舗 ID がメッセージのキーになるように変換して、同一店舗のデータに由来するメッセージは同一パーティションに、データベース更新時の順序を保持したまま発行されるように設定しました。10 Debezium + Kafka Consumer のシステムで順序一貫性を保証するには、Debezium から Apache Kafka にメッセージ発行する時点でパーティションのキーを選択して、以後は処理システムの最後までメッセージのキーを変更しないように設計する必要があります。11
まとめ
このように Debezium と Apache Kafka エコシステムの組み合わせは、様々なシステムの課題に対応した設計パターンを実現できる力を持っています。これはメッセージングが現代的な分散システムの重要なポイントの一つであり、Apache Kafka はメッセージングの様々な課題を解決するために開発されたプロダクトであることから、当然の帰結であるとも言えます。
マイクロサービス化チーム・基盤ユニットでは Debezium のような基盤技術を武器としてサービス開発エンジニアに提供し、アプリケーションを高凝集・疎結合な設計にリファクタリングする業務をしています。
ご興味のある方は、ぜひ採用サイトからご連絡をください! エンジニア組織の文化風土などを面接前に知りたい方は、本採用プロセス前にカジュアルな面談から対応できます。フリーコメント欄に「カジュアル面談希望」とご記載ください。ご応募お待ちしております!

- 食べログのレストラン検索を支える Debezium と Apache Kafka - Qiita↩
- 食べログの内製Pub/Subメッセージング基盤をApache Kafkaにリプレイスした話 - Qiita↩
- クラウド型の ETL ツールを提供する Integrate.io 社のブログから一部引用いたしました。 Change Data Captureとは? | Integrate.io↩
- 食べログではメインのデータベースに MySQL を採用している都合から、本記事ではデータベースは MySQL で説明してゆきます。Debezium は MySQL 以外にも PostgreSQL や Microsoft SQL Server にも対応しています。食べログでは MySQL と Debezium の組み合わせは信頼できると判断して採用していますが、他のデータベースとの組み合わせについては知見がありませんので、その点ご承知おきください。↩
- とは言え効率化する習慣はなかなか抜けないのか、新システムに切り替えてからの全件更新は、私が認知しているところでは1回しか実施されていません。↩
- 食べログノートの詳細はフロントエンドエンジニアブログで紹介されているのでぜひご覧ください。 食べログノートをリリースしました!|食べログ フロントエンドエンジニアブログ|note↩
- Kafka Connect JDBC Connector は Confluent 社がメンテナンスしており Confluent Community License で提供されています。confluentinc/kafka-connect-jdbc: Kafka Connect connector for JDBC-compatible databases↩
- CQRS パターンについては Microsoft 社の Azure サポートサイトに良くまとまった説明があります。 CQRS パターン - Azure Architecture Center | Microsoft Learn↩
- Transactional outbox パターンについてはマイクロサービスアーキテクチャの情報を数多く提供している microservices.io に大変良くまとまった説明があります。 Transactional outbox - microservices.io↩
- SMTs については Apache Kafka の公式サイトで体系的な説明が見つけられませんでしたが、Apache Kafka の主要なコントリビュータ企業である Confluent 社のドキュメントに詳しい説明があります。 Get started with Single Message Transforms for self-managed connectors | Confluent Documentation↩
- Apache Kafka のメッセージのパーティショニングが途中で変わることで順序が保証されなくなる現象を shuffling と言います。Confluent 社の別のプロダクトである ksqlDB の解説記事にわかりやすいアニメーション図解があります。 How Real-Time Materialized Views Work with ksqlDB↩