目次
- 目次
- はじめに
- そもそもシステム運用改善チームとは何か?
- なぜアプリAPIのパフォーマンス改善が必要になったのか?
- どうやって改善箇所を見つけるのか?
- 分散トレーシングを使って、店舗詳細APIを細かく分析する
- 計測結果から見つけたポイントに改善を実施していく
- 全体での改善効果はどうだったか?
- パフォーマンス改善の影響
- 食べログの分散トレーシングを使って改善を実施してみてよかったこと
- おわりに
はじめに
こんにちは。食べログ開発本部 ウェブ開発1部 システム運用改善チームの @4palace です。 今回は、私の所属するシステム運用改善チームが食べログアプリAPIのパフォーマンス改善に取り組んだ事例を紹介します。 分散トレーシングを活用することで、食べログアプリAPIのレスポンスタイムをコスパよく2割改善できました。
まずは、システム運用改善チームが食べログの中でどういう領域を担当しているのかを紹介します。
そもそもシステム運用改善チームとは何か?
システム運用改善チームは、Ruby on Railsでサーバーサイド開発を行うチームです。 普段からシステムの設計課題解決やパフォーマンス改善など、システムそのものの改善活動を中心に行なっています。 このチームの最も大きな特徴は、企画メンバーがいないことです。
企画メンバーとは、「ユーザーさんのためにこういった施策をやりたい!」という方向性を決める人たちのことを指します。 通常、食べログのサーバーサイド開発では企画担当やデザイナーとタッグを組み、システムの機能開発を行うことがほとんどです。
企画メンバーがいないシステム運用改善チームでは、エンジニア自ら施策の方針を決めて取り組む必要があります。 エンジニアが施策立案をする事で、ユーザー目線では見えづらいシステム面の課題解決や、運用面での改善に目を向けられるという特徴があります。
なぜアプリAPIのパフォーマンスを課題としたのか?次の章では、その背景を説明します。
なぜアプリAPIのパフォーマンス改善が必要になったのか?
食べログアプリでは、APIで店舗情報を取得し、店舗詳細画面を表示しています。 店舗詳細APIは1日で1000万回以上のアクセスがあります。 この店舗詳細APIのレスポンスタイムが緩やかに悪化していることがわかっていました。
急激に悪化したタイミングは無いため特定のリリースが原因とは考えにくく、 食べログアプリに対して、以下の変化があったことが原因と考えられました。
- 食べログアプリの利用者数が増加傾向であること
- コンテンツが増え、APIで返却するデータ量が増加していること
アプリ利用者およびコンテンツ量の増加は食べログの成長の証です。嬉しい反面、今後これらが大きく減ることは想定しづらく、 何らかの改善が必要だと感じていました。このため、APIの性能改善は必要かつ重要な課題でした。 これを踏まえて、本格的な食べログアプリAPIのパフォーマンス改善に取り組むことにしました。
どうやって改善箇所を見つけるのか?
食べログでは全てのAPIに対して1日平均レスポンスタイムの計測を行っています。 ですが、店舗詳細APIの1日単位での平均レスポンスタイムからは、どの部分が遅いのか、どの部分を改善すれば良いかが掴みにくい状態でした。
そこで、食べログで整備されていた分散トレーシングを利用することにしました。 分散トレーシングでは、内部の1リクエストよりさらに細かい単位での処理時間の分析が可能になります。 これを用いて、どの部分が遅いのか、どの部分で改善を行うと効果的なのかを特定できると考えました。
次の章では、分散トレーシングを使うことで、どのように計測が変わり、どう活用できるのかを紹介します。
分散トレーシングを使って、店舗詳細APIを細かく分析する
分散トレーシングの仕組みについてご興味のある方は、以下の弊ブログの記事をご覧ください。 大規模サービスにマッチした可変レート分散トレーシング - Tabelog Tech Blog
食べログの分散トレーシングを使って計測できることは以下の3点です。
- SQL発行内容
- SQL発行回数
- SQL1本あたりの処理時間
店舗詳細APIは様々なテーブルから情報を集めているため、必然的にSQL発行本数は増えます。 SQLの組み方が悪いと、全体に対するパフォーマンス影響も大きくなります。 どのSQLの処理に時間がかかっていて、どこを直せば改善効果が高いかを判断できるようになることで、効率的な改善が可能になります。
調べたい部分を計測対象に追加することで、分散トレーシングの計測を開始することができます。 今回の場合は、店舗詳細APIのControllerに以下のような1行の設定を追加しました。
# rate_for_traceは計測対象とするリクエスト割合 trace_action :show, rate: rate_for_trace
それでは、実際にお店詳細APIを分散トレーシング計測した結果を確認していきます。
計測結果の見方
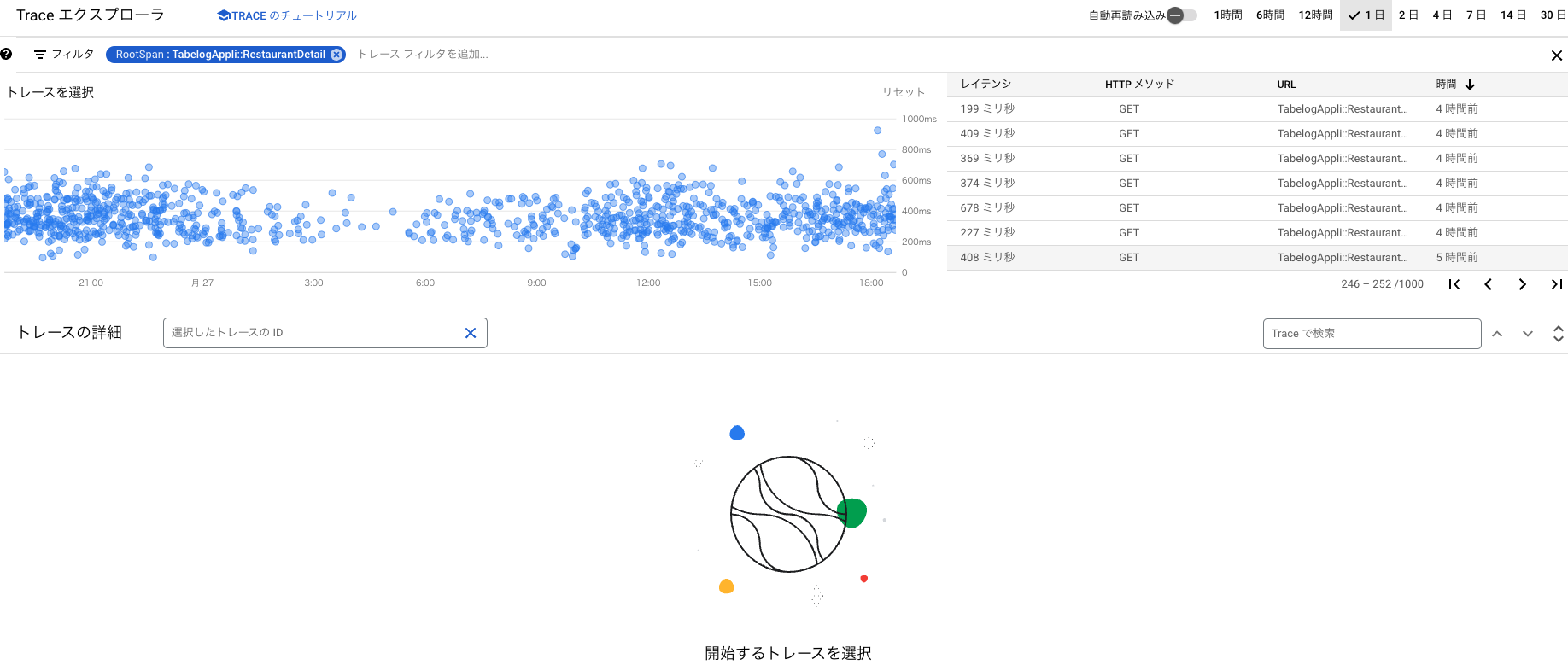
分散トレーシングの計測結果はGoogle Cloud Platform(GCP)のTrace エクスプローラという画面で確認できます。 以下の図1は、Traceエクスプローラの画面です。 画面上部の「トレースを選択」の部分にトレース結果を表す粒(水色)が表示されています。粒ひとつがひとつのリクエストを表していて、レスポンスタイムが大きいものが散布図の上側に表示されます。
図1: Traceエクスプローラの画面
1つの粒を選択すると、図2の画面に切り替わります。下部にトレースの詳細が表示されます。
図2: トレースの詳細画面
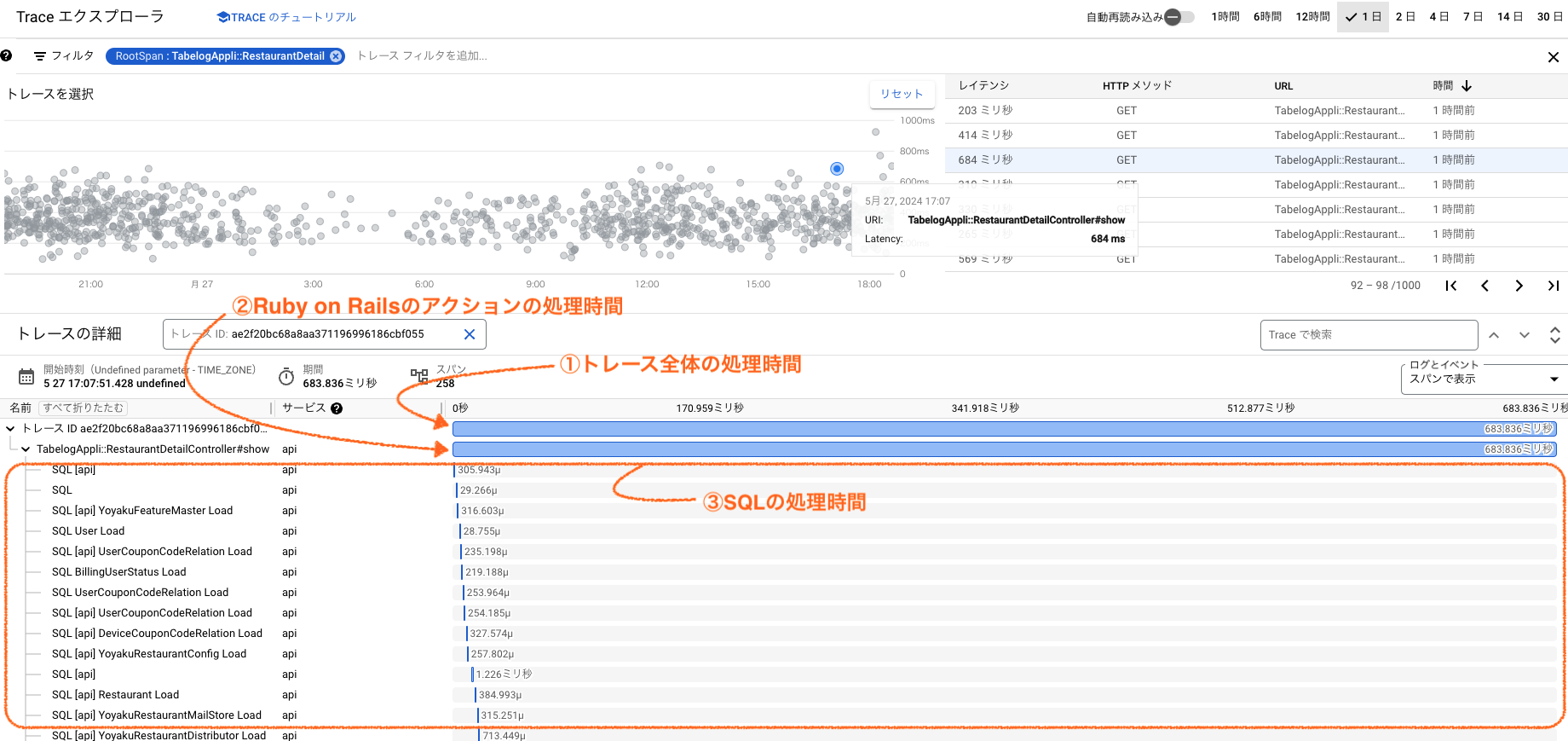
トレースの詳細画面では、行ごとに水色の長方形が表示されています。 長方形の横幅が処理時間を表しています。
①はトレース全体の処理時間を表しています。 ②はRuby on Railsのアクションの処理時間を表しています。
今回注目したのは赤く囲んだ③の部分です。SQL から始まる名前の行は、SQLの処理時間を表しています。
ActiveRecord経由で発行されたものはActiveRecordモデル名も表示されています。
この画面を見て、ある処理が他の処理と比べて時間がかかる処理かどうか確認することができます。 時間がかかる処理であれば、そこにパフォーマンス上の問題を抱えている可能性があります。
以上のように、分散トレーシングで計測対象としたリクエスト一覧から、 レスポンスタイムの大きいもの(より上にある粒)を選択し、 そのトレース詳細を見て、どの青い長方形が横に長いかを確認することで、時間がかかっている部分を確認することができます。
これを繰り返し、複数のリクエストで同じ傾向があり、なおかつ時間がかかっていた部分を観察することで、 効果的に改善できる部分を抽出していきました。
計測結果から分かったこと
店舗詳細APIにおいては、以下のSQL発行が遅いことがわかりました。
- コースに紐づくクーポンの取得
- 口コミを取得する処理と公開画像数のカウント
- ユーザーごとの公開口コミ投稿数の合計数カウント
次の章では、発見したそれぞれのポイントに対して、どのような改善を実施したかを示します。
計測結果から見つけたポイントに改善を実施していく
ここからは、計測結果から見つかった3つの改善ポイントに対して、どのような改善を行ってどのような効果があったかを紹介します。 改善の効果は、曜日によって差があるため、前週の同曜日とレスポンスタイムを比較して改善効果を確認しました。
それでは、改善ポイントごとに説明していきます。
コースに紐づくクーポンの取得
食べログでは、特定のコースでのみ利用できるクーポンがあります。 店舗詳細APIの中で、お店に紐づくコースごとにクーポンの取得を行っています。 分散トレーシングの結果を確認すると、1店舗あたりのクーポンデータ量はさほど多くないはずなのに、SQLの1本あたりの処理時間が長くなっていました。
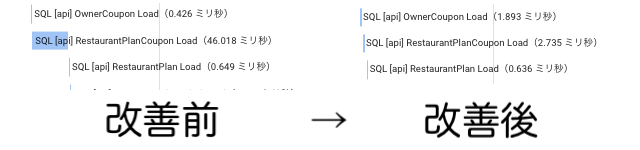
以下の図3はトレース詳細の一部です。
真ん中のRestaurantPlanCoupon Load がクーポン取得のSQL処理時間を示しており、46.018ms かかっています。
前後のSQL処理時間と比べると時間がかかっていたことがわかります。
図3: 改善前後の比較
RestaurantPlanCoupon のSQL処理時間がかかる理由を探るため、SQLのEXPLAINステートメントを使って実行計画を確認しました。
コースごとにクーポン絞り込みをおこなっているカラムではindexを使っておらず、ほぼフルスキャンとなっていることがわかりました。
適切なindexを貼ることで、SQL処理時間を短縮できました。
真ん中のRestaurantPlanCoupon Load が 2.735ms に変化し、改善前と比べると処理時間が削減できていることがわかります。
クーポンを設定しているお店では本施策の改善により処理時間が約43ms改善されているお店もありました。 レスポンスタイムの1日平均を確認すると、前週同曜日と比べ、10ms 改善されていました。
| 改善ポイント | 改善内容 | 改善効果 |
|---|---|---|
| コースに紐づくクーポンの取得 | テーブルへの適切なindex付与 | 10ms |
口コミを取得する処理と公開画像数のカウント
店舗詳細ページには、お店に投稿された口コミ3件とそれに紐づく投稿画像が表示されます。 口コミや投稿画像が非常に多く投稿されたお店では、表示する口コミや投稿画像を取得する処理が遅いことがわかっていました。 人気店舗では紐づくデータ量が多く、テーブルから表示条件に合う口コミおよび投稿画像を選択する処理が大きなコストとなっていました。
以下の図4-1における水色のSQL[api] RestaurantOwnerSetting Load と SQL[api] Bookmark Load の間の行が、表示する口コミや投稿画像を取得する処理です。
この行のSQL発行だけで270msもの時間を占有していることがわかります。
改善後の同一箇所のトレース結果が以下の図4-2です。
SQL[api] RestaurantOwnerSetting Load と SQL[api] Bookmark Load の間で取得していた口コミの取得処理がキャッシュ利用により省略されていることがわかります。
270msかかっていた処理が 1ms 未満に改善されました。
図4-1: 改善前
 図4-2: 改善後
図4-2: 改善後

「コースに紐づくクーポンの取得」と同様にindexの付与も検討しましたが、テーブルが非常に大きく、現実的ではありませんでした。
改善方法を探るため、お店の口コミおよび投稿画像を取得する処理の特性を整理しました。
- 表示する口コミ数は3件で固定
- 口コミの選択コストが高い
- 人気店舗ほどデータ量が多いため、選択コストは大きくなる
- 口コミ/投稿画像のIDが決まっていれば高速に取得できる
- アクセスごと/ユーザーごとに抽出される3件の口コミが変わることはない
- 店舗IDと口コミ3件の紐付け結果はしばらく使い回すことができる
- 人気店舗では1日に数多くアクセスが行われるため、再取得頻度が高い
以上の特性から、一度選択された口コミ/投稿画像のIDをキャッシュとして再利用することにしました。 コストが大きい口コミ選択処理の実行頻度を抑えることで、処理速度の改善が見込めます。
レスポンスタイムの1日平均を確認すると、前週同曜日と比べ、25msの改善が見られました。
| 改善ポイント | 改善内容 | 改善効果 |
|---|---|---|
| 表示する口コミの取得と公開画像数のカウント処理 | 店舗の取得口コミとカウントのキャッシュ化 | 25ms |
ユーザーごとの公開口コミ投稿数の合計数カウント
店舗詳細APIの計測結果を見ると、SQL発行回数が多い部分がありました。 店舗詳細ページでは、表示する口コミの投稿ユーザーごとに公開口コミ数の表示をしています。 発行回数の多いSQLはこの公開口コミ数カウント処理であることがわかりました。
実装を確認すると、ユーザーごとに別々のSQL発行を行なっており、SQL発行回数が増えていました。
図5-1の SQL[api] と記載された部分で発行しているSQLが、ユーザーごとの公開口コミ数のカウントに該当します。
図5-1: 改善前

SQL発行回数を減らすため、公開口コミ数をユーザーごとではなく、1店舗分まとめて取得するようにSQLを見直すことで、SQL発行回数を減らしました。
改善実施後の結果が以下の図5-2です。
図5-2の 4行の処理結果は図5-1の SQL[api] で示された行と同じ結果を表示するために発行されたSQLです。
つまり、同じ内容を表示するために発行したSQLの数と処理時間が共に減っていることを示しています。
図5-2: 改善後

レスポンスタイムの1日平均を確認すると 前週同曜日と比べ、120ms程度の改善が見られました。
| 改善ポイント | 改善内容 | 改善効果 |
|---|---|---|
| 各ユーザーの公開口コミ数カウント処理 | 公開口コミ数カウント処理の効率化 | 120ms |
全体での改善効果はどうだったか?
3つの改善施策をリリースした結果を表に示します。
| 改善ポイント | 改善内容 | 改善効果 |
|---|---|---|
| コースに紐づくクーポンの取得 | テーブルへの適切なindex付与 | 10ms |
| 表示する口コミの取得と公開画像数のカウント処理 | 店舗の取得口コミとカウントのキャッシュ化 | 25ms |
| 各ユーザーの公開口コミ数カウント処理 | 公開口コミ数カウント処理の効率化 | 120ms |
改善前は800ms程度だった店舗詳細API の平均レスポンスタイムを645ms程度に改善することができました。 155ms改善したので、2割近く平均レスポンスタイムを短縮できたことになります。
3つの改善施策によって、DBサーバーのCPU負荷も低減されました。 改善前はDBサーバーの1台あたり最大CPU使用率が 26%程度だったものが、12%程度まで下がりました。 APIのリクエスト数は減少していなかったことから、それぞれのデータ取得処理の負荷が下がったことで、全体のCPU使用率も軽減されていたと考えられます。
店舗詳細APIは1日1000万回以上実行されるAPIのため、小さな改善でもDBサーバーの負荷軽減には効果があると考えていました。 結果的には2割近くレスポンスタイム削減が実現できたことで、大きくDBサーバーのCPU負荷軽減にもつながりました。
レスポンスタイム/DBサーバーのCPU負荷の両面で、パフォーマンスの改善を確認できました。
パフォーマンス改善の影響
このAPIのパフォーマンス改善がアプリに与えた影響としては以下が挙げられます。
- ユーザー体験が向上した
- 今後の食べログ成長に備えたシステム上の余裕ができた
ユーザー体験が向上した
店舗詳細ページはユーザーがお店を探すときに必ず表示される画面です。 店舗詳細APIのレスポンスが改善されたことにより、ユーザーのお店探し体験が向上したといえます。
お店によって表示コンテンツの量が異なるため、店舗詳細APIのレスポンスタイムはお店ごとに差があります。 今回の施策によって、クーポンを設定していたお店や、アクセス数が多く口コミが多いお店では平均値以上の改善がみられ、ユーザー体験が大きく向上しました。 人気のお店では、「表示する口コミの取得と公開画像数のカウント処理」の効果でレスポンスタイムが300ms近く改善されたケースもありました。 人気のお店を探す時ほどユーザー体験に好影響を与えたと考えられます。
今後の食べログ成長に備えたシステム上の余裕ができた
食べログは、店舗詳細APIだけでも1日1000万回以上のアクセスがあります。 1本あたりの負荷を数%でも下げることができれば、リクエストの処理に必要なサーバー台数を減らすことができます。
パフォーマンス改善実施後、インフラを担当するSREチームから 「今回の改善によりDBサーバーの負荷が大きく下がったことで、サーバーの更新に伴う台数確保に余裕ができ非常に助かった!」 との声をいただき、嬉しく思いました。
食べログの分散トレーシングを使って改善を実施してみてよかったこと
今回、食べログで整備されていた分散トレーシング機構を本格的に改善に利用しました。 分散トレーシングはパフォーマンスチューニングの非常に強力なツールでした。 特に強力だと感じた点はこちらです。
- 計測導入が非常に楽
- 改善箇所をピンポイントで特定できる
今回のAPIへの計測導入は非常に楽でした。大きな設計変更も不要で、調べたい部分をすぐに計測でき、結果確認も簡単にできました。 また、改善箇所をピンポイントで特定できたため、改善施策の方向性も明確に定められました。 リリース後の効果確認も容易に行えるため、コスパ良く改善を実施できました。
おわりに
システム運用改善チームでは、皆さんがよく目にする食べログを快適かつ安定的に提供すべく日々改善に努めています。
システム運用改善チームで働くことに興味を持たれた方は、ぜひ採用サイトからご連絡いただけると幸いです!
