目次
- 目次
- はじめに
- 分散システム視点での自動テストシステム
- 事例:食べログで起きた分散システム視点でのFlakyテスト
- 学び: 自動テストシステムに求められる分散システム設計
- まとめ
- 採用リンク
- 参考文献
はじめに
食べログシステム本部の品質管理室でテックリードをしている荻野です。ここ数年アドベントカレンダーなどのブログ記事ではアジャイルやDevOpsの歴史や考え方を書くことが多かったのですが、今年はがっつり自動テストのプログラミングについて書いてみようと思います1。
2014年に"システムテスト自動化標準ガイド"が日本でも出版されてから、テスト自動化について当たり前のように取り組む組織が増えてきました2。1999年に原著が出版された当時はテスト自動化はまだまだ黎明期でありソフトウェアとしての仕組みがまだまだ確立していない時代だったため、この本の焦点はソフトウェアとしてのテストケースの保守性や堅牢性に焦点を当てられています。
2014年にこの本の日本語翻訳版が出版され日本でもテスト自動化が普及すると、Flakyテストの問題が議論されるようになりました3。Flakyテストはテスト実行ごとに毎回テスト結果が成功したり失敗したりと変わってしまうテストで、その原因調査や修正に時間を要してしまいます。そのためFlakyテストが増えると、テスト自動化によってテスト実行のコストは抑えられるものの、テスト結果の確認やテストコードのメンテナンスなどのコストが増えてしまうという問題が発生します。特に近年のテスト自動化は単純なスクリプトとして実装されることよりも、大量のテストケースを実行するために複数コンポーネントをクラウドやコンテナ環境で連携させながら動かす分散システム構成となっていることが多く、そのことが原因となるFlakyテストも増えています。
このブログ記事では、食べログの自動テスト分散システムで生じたFlakyテストの問題を元に、自動テストシステムに求められる分散システムの設計について解説します。前半では食べログの自動テストで生じたFlakyテストの問題について詳細をご紹介しますが、さっくりと分散システムの設計についてご覧になりたい方は「学び:自動テストに求められる分散システム設計」まで読み飛ばしていただいて大丈夫です。
分散システム視点での自動テストシステム
分散システム構成
まず最初に、食べログの自動テストシステムを分散システムの視点で見てみましょう。
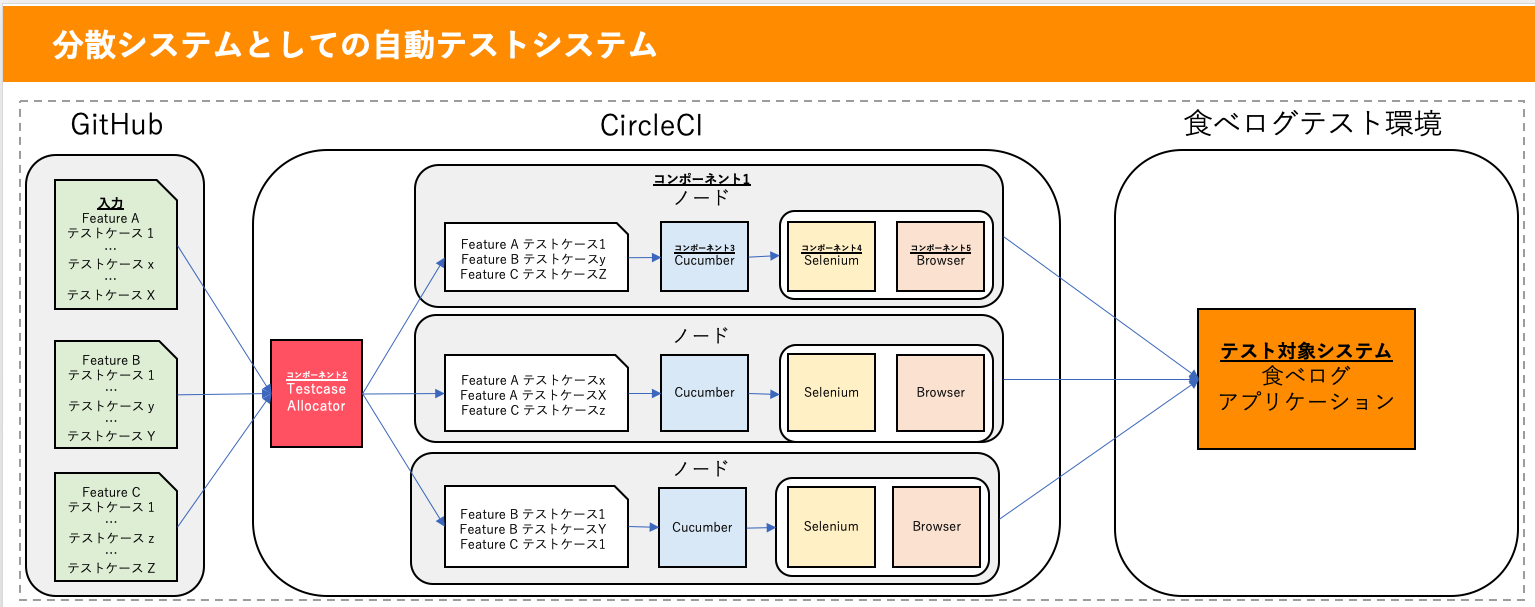
本ブログでは自動テストシステムの定義を
- 入力としてテストケースを受け取って
- テスト対象システムにテストを自動実行し、
- テスト結果をレポートとしてまとめる (上記図中では省略)
するシステムとします。
少数の単体テストなどを自動化する場合は単純なソフトウェアとして自動テストを構成することも多いですが、それなりの規模のE2Eのテストケースを自動化する場合にはテスト実行環境となるノードを複数並べてスケールアウトする必要が出てきます。また、分散システムを構成するコンポーネント視点で見ると「テストケースを複数のノードに分配するコンポーネント」「テストケースの実行ステップを自動実行するコンポーネント」「ブラウザ操作を実行するコンポーネント」など、複数のコンポーネントがあります。これらの分散システムとしての自動テストシステムについて食べログの構成の詳細をみていきます。
入力

自動テストシステムへの入力はテストケースです。食べログでは数百のEnd to EndのテストケースをCucumberの振る舞い駆動開発(BDD)形式で管理しており、管理の単位は「ログイン」「予約」などのテスト対象システムの機能(Feature)単位となっています4。すべてのテストケースはGitHub上でバージョン管理されています。
出力
自動テストシステムの出力は自動実行したテスト結果をまとめたテストレポートです。自動テストは複数のノードで分散実行されるので、ノードごとに出力されるテスト結果をマージし1つのテストレポートとしてまとめます。(上記図中では省略、下記が実際のレポート。)
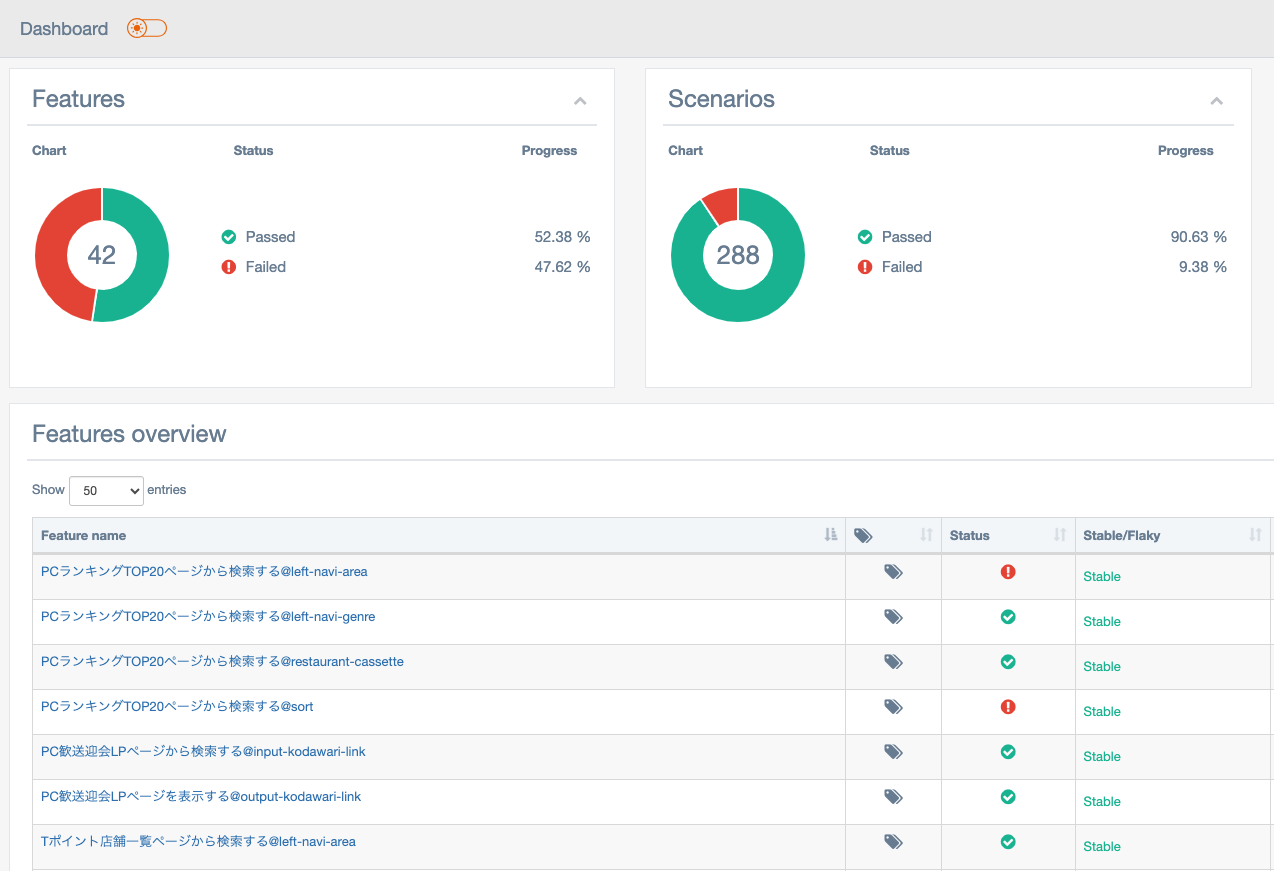
テスト対象システム

食べログの自動テストシステムのテスト対象システムは、もちろん食べログサービスが動いているシステムのテスト環境です。食べログのオンプレミスのデータセンターに食べログを構成するアプリケーション、DBなどのシステムがデプロイされています。
コンポーネント
ノード

ノードは大量のテストケースを分散し並列実行する仕組みの肝となるコンポーネントです。1つのノードの中には、Cucumber(テストケースの実行ステップを自動実行するコンポーネント)、Selenium(ブラウザ操作を実行するコンポーネント)などのテスト自動化に必要なコンポーネントがすべてデプロイされており、単独でテストを自動実行可能です。このノードを複数並べテストケースをそれぞれのノードで分散実行することで、比較的実行時間のかかるE2Eの自動テストを短時間で完了できるようになります。食べログでは全部で31ノードで分散することで15分でテストを完了できるようにしています。
Testcase Allocator

Testcase Allocatorは数百からなるテストケースをそれぞれのノードに割り当てます。食べログでは割り当て方式を実行時間としており、過去の実行時間実績からすべてのノードで均等な実行時間になるように割り当てるコンポーネントをCircleCIの機能をベースに自作しています5。割り当てにはテストケースの管理単位であるFeatureは考慮しないため、テスト実行時には1つのノード上で異なるFeatureのテストケースが混ざり合って実行されます。
Cucumber

Cucumberはテストを自動実行するコンポーネントで、ノード上でテストケースのテスト実行ステップを順次実行します6。テスト実行ステップの中でブラウザを操作したテスト対象環境へのアクセスが必要な場合はSeleniumと通信し、SeleniumのAPIを通じてブラウザを操作します。また、ブラウザ操作などのテスト実行ステップがタイムアウトや対象のHTML要素がないなどの原因で失敗した際の例外処理も担当しています。
(※ Cucumber自体はテストケースの並列実行もサポートしていますが、食べログではノードで分散処理を実現していますのでこの機能は使っていません。)
Selenium

Cucumberから与えられたブラウザ操作をもとにBrowserの自動操作を実行します7。1つのノードに1つずつSeleniumはデプロイされており、同じノード上のテストケースは1つのSeleniumを使い回しています。
Browser

Seleniumを通し操作が実行され、実際に食べログのテスト対象環境にアクセスします。分散構成図で示しているように1つのノードに1つずつBrowserはデプロイされており、同じノードで実行されるテストケースは1つのBrowserを使い回しています。ただし通常はテストケースは順番に実行され、1つのテストケースのBrowser利用が完了してから次のテストケースがBrowser利用を開始するため複数のテストケースが同時に1つのブラウザにアクセスすることはありません。
事例:食べログで起きた分散システム視点でのFlakyテスト
問題
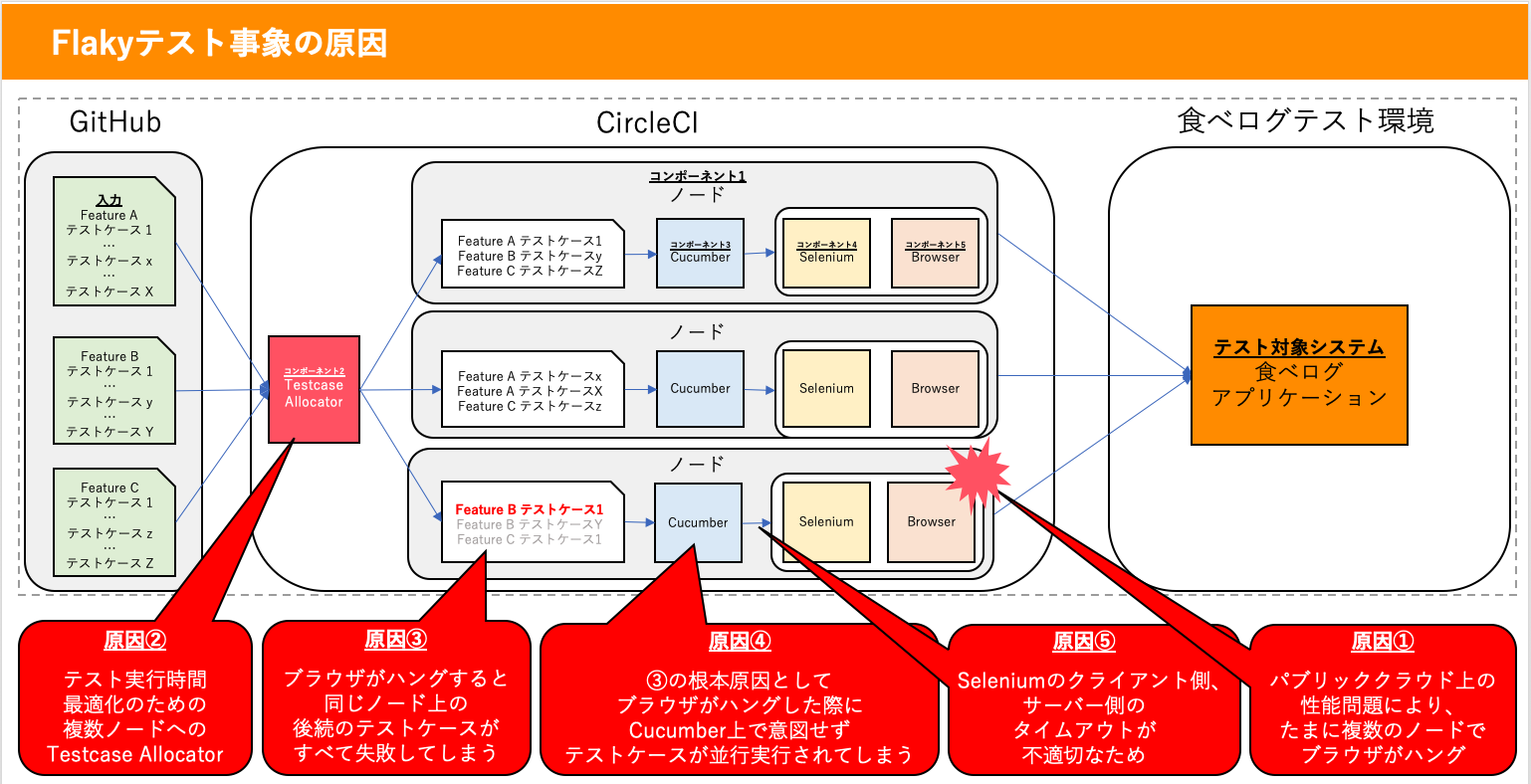
Flakyテストの事象: "たまに" "不特定" "多数のテストケースが" "Cucumberのstepの60秒タイムアウトエラーで失敗する"
食べログで起きていたFlakyテストの事象は
- 事象A: たまに(4回に1回程度の頻度で)
- 事象B: 不特定 (毎回異なるテストケース)
- 事象C: 多数のテストケースが(テストケース全体の20~70%程度)
- 事象D: Cucumberのstepの60秒タイムアウトエラーで失敗する
というものです。
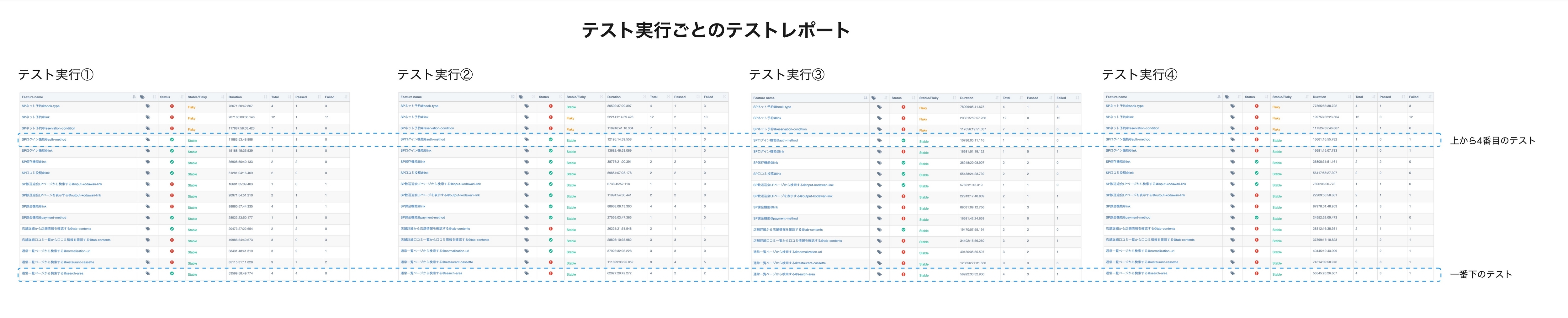
こちらは[事象B]と[事象C]を表した、flakyが発生したテスト実行のテストレポートを4回分まとめたものです。緑のテストケースが成功しているテスト、赤のテストケースが失敗しているテストです。一見たくさんのテストケースが失敗しているなという印象ですが、細かくみてみると
- 上から4番目のテストはテスト実行④だけ赤く失敗
- 一番下のテストはテスト実行①だけ緑色で成功
しており、テスト実行ごとに失敗するテストケースが変わってしまっていることがわかります。
また事象Dについては、失敗しているテストケースのほとんどでは

というエラーログが出ていました。こちらはCucumberが1つの実行ステップを60秒以内に完了できなかった場合のタイムアウトエラーです。このエラーログからわかることは、失敗するテストでは何かしらの処理を60秒以内に完了できていない問題が起きていることでした。
Flakyテストの原因調査の複雑さ
Flakyテストの原因調査は、通常のテスト失敗に比べて複雑です。通常のテスト失敗では「ログインできない」「予約できない」などのテスト結果が100%再現できます。そのため、その結果を引き起こしうるソースコード箇所を特定しながら原因調査を進めます。しかしFlakyテストでは、テスト実行ごとに「ログインできる」「ログインできない」と、テスト結果が毎回変わってしまいます。そのためテスト結果を100%再現することが難しく、原因となるソースコード箇所の特定が複雑になってしまいます。
さらに今回経験した事象では、テスト結果だけが変化するわけでなく、結果が変わるテストケース自体もテスト実行ごとに毎回変化してしまっていました。毎回異なるテストケースが全体の20~70%くらい失敗してしまっており、テスト失敗の原因調査のためどのテストケースを調査すればよいのかわからないと言う状態でした。
勘の良い方ならばもうお気づきかと思いますが、こういった事象は単独のテストケースやプログラムコードが原因としては起こりにくいものです。食べログの自動テストはTestcase Allocator、Cucumber、Seleniumなどの複数のコンポーネントによって構成される分散システムになっていますが、今回の事象はそれら複数のコンポーネントが原因で複雑な事象として表出していました。
原因と対策
ざっくりと今回のFlakyテストの事象の原因をまとめると、「ノード上でブラウザがハングした際に、後続のテストケースを巻き込みすべて失敗させてしまう」というものでした。下の図中の一番下のノードで「Feature B テストケース1」を実行中にブラウザがハングしてしまうと、そこから回復できず、そのノード上で実行される後続のテスト「Feature B テストケースY」と「Feature C テストケース1」も巻き込んで失敗してしまっていました。
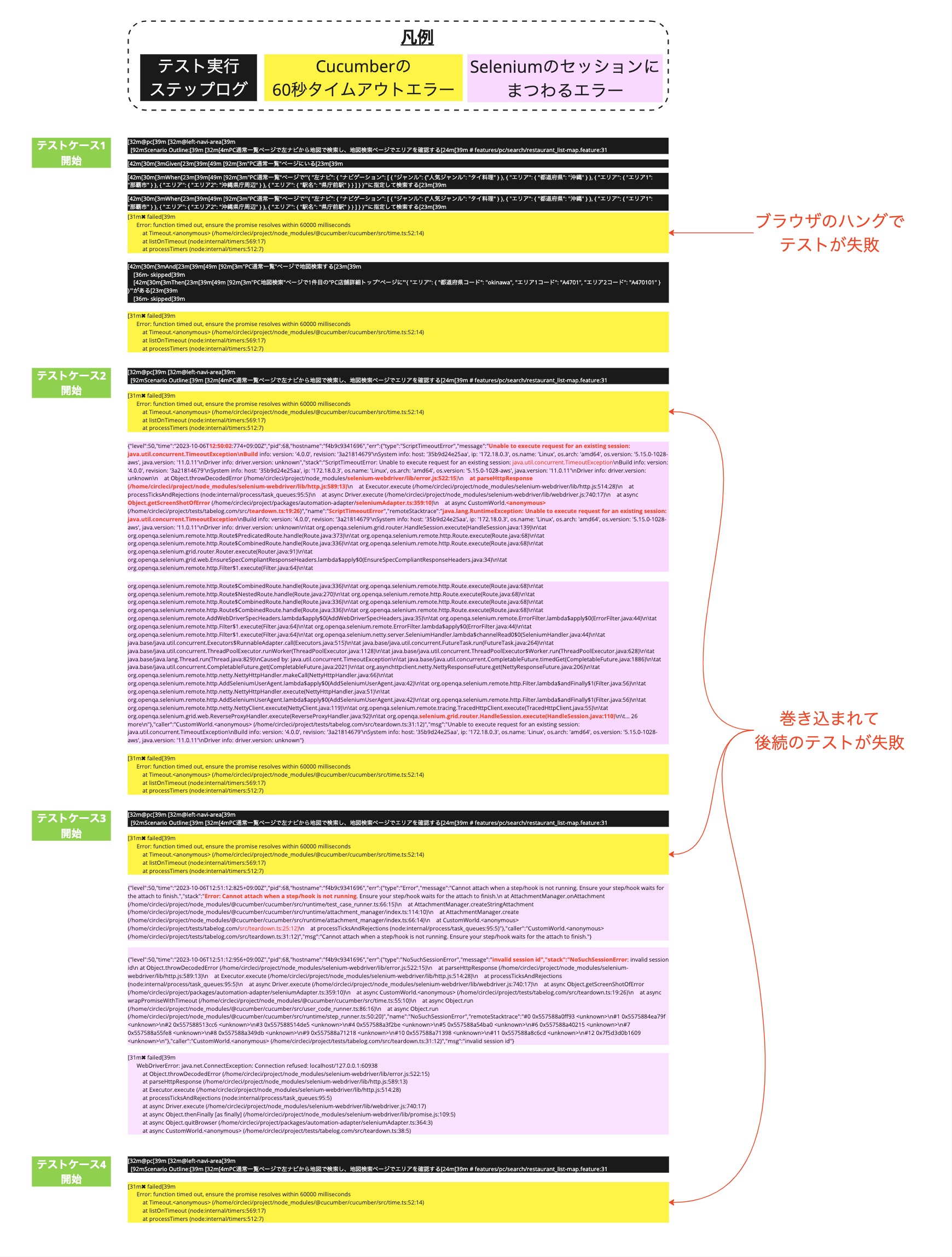
わかってしまえば原因自体は単純なものでしたが、自動テストシステム上の複数のコンポーネントの原因が複合的に作用し事象の見え方が複雑化していました。以下に、今回のFlakyテストの事象と原因、対策をまとめます。
| 事象 | 原因となるコンポーネント | 原因 | 対策 |
|---|---|---|---|
|
Browser
|
原因① パブリッククラウド上の性能問題により、たまに複数のノードでブラウザがハング |
|
|
Testcase Allocator
|
原因② テスト実行時間最適化のための複数ノードへのTestcase Allocator |
|
|
ノード Cucumber |
原因③ ブラウザがハングすると同じノード上の後続のテストケースがすべて失敗してしまう 原因④ ③の根本原因としてブラウザがハングした際にCucumber上で意図せずテストケースが並行実行されてしまう |
|
|
Cucumber ⇄ Selenium |
原因⑤ Seleniumのクライアント側、サーバー側のタイムアウトが不適切なため |
|
「事象A: たまに(4回に1回程度の頻度で)」の原因と対策
「たまに」自動テストが失敗してしまう原因はパブリッククラウド上の性能問題により、ノードでブラウザがハングしてしまうからでした。パブリッククラウドでは1つの物理サーバー上でたくさんのノードが動いており、他のノードの負荷が上がった際に自分が使っているノードが影響を受けてしまうことがあります8。そのため、たまにブラウザがハングしてテストケースが失敗すると言うことが起きていました。また、当初20~70%程度のテストケースが失敗していてびっくりしましたが、実際にブラウザがハングしているテストケースの発生割合は多い時でも全体の5%程度で、残りのテスト失敗の原因は「原因③」のハングしたブラウザを使い続けていることでした。
この原因①については直接的な対策はせずいったんは様子見としました。理由は、この原因で失敗しているテストケースは多くても全体の5%程度であり、残りの15~65%のテストケース失敗は事象Cで後述するものが原因であり、そちらを改善することを優先したためです。Flakyテストの完全な撲滅は難しく、Googleでは7つのテストケースのうちの1つ、またGitHubでは23%から24%のテストケースになにかしらのFlakinessがあると言われています9。そのため、やみくもにすべてのFlakyテストを修正するのではなく、Flakyテストの発生率と発生テストケース数から優先順位を決めて修正に取り組むことが重要と言われています。このケースについては、発生率が4回に1回程度であり発生割合も5%のため、いったん様子見としています。
ただし、今後の原因調査やノードの増強計画のため、パブリッククラウドの性能監視項目を増やしました。
「事象B: 不特定 (毎回異なるテストケース)」の原因と対策
毎回異なるテストケースが失敗している原因は、Testcase Allocatorがノードで実行するテストケースを毎回シャッフルしているからでした。Featureファイルごとなど毎回同じ条件でテストケースをノードに分配する仕組みであれば、もしかしたら失敗するテストケースに一定の規則性が出ていたかもしれません。ですが、今回の事象ではテスト実行時間のみを条件としてテストケースをノードに分配していたため、巻き込まれて失敗するテストケースも規則性なく毎回変わっていました。
こちらの原因についても対策は実施していません。テスト実行時間を均一にするため毎回シャッフルすること自体は意図通りであり、それよりも巻き込まれることによって後続のテストが失敗してしまう「事象C」の問題を解決することにしました。
「事象C: 多数のテストケースが(テストケース全体の20~70%程度)」の原因と対策
多数のテストケースが失敗してしまう原因は、ブラウザがハングすると同じノード上で実行される後続のテストケースがすべて失敗してしまうことでした。これは同じノード上で実行されるテストケースではSeleniumとBrowserが共有されており、かつ、一度ハングした際に適切なエラー処理が行われておらず回復しないことが原因でした。
またこの問題を根深くしてしまった原因として、テストケースの順次実行が保証されているはずのCucumber上でブラウザがハングした際に意図せずテストケースが並行実行されてしまうというものがありました。本来Cucumberではテストケース1、テストケース2、テストケース3と順次実行が保証されていますが、ブラウザがハングした際には一見テストステップ自体は進んでいてもバックグラウンドではSeleniumとの通信のセッションがハングした状態で継続していました。そのため、テストケース1、テストケース2、テストケース3とすべてのテストケースが同時にSeleniumを通しBrowserの操作を試んでいましたが、Browserは1つしかないため最初のテストケース以外の操作はタイムアウトしていました。
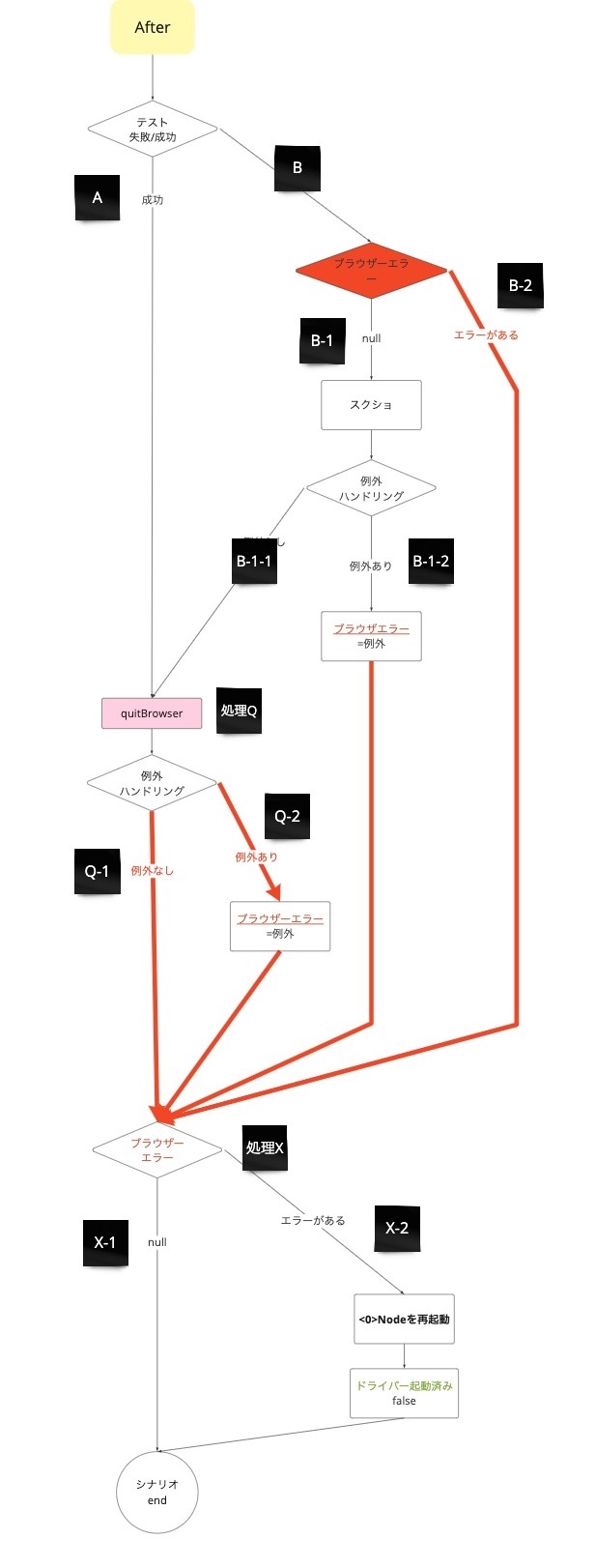
これらの原因に対する対策の1つ目として、自動テストシステムで実施しているSeleniumのBrowser操作を整理し、エラー処理を再設計しました。食べログの自動テストシステムではSeleniumを通したBrowser操作を
- テスト準備ステップ(Before)で、Selenium WebDriverの初期化
- テスト実行ステップで、実際のBrowser処理
- テスト終了ステップ(After)で、テスト失敗時のスクリーンショットの取得とSelenium WebDriverのクローズ
の3種類行っています。それぞれの処理の失敗時にブラウザエラーを返すようにし、このエラーが発生したらテスト終了ステップでSeleniumとBrowserを再起動するようにしました。こうすることで、自動テスト実施中にBrowserハングが原因でテストが失敗しても、次のテストケースからはクリーンなBrowserでテスト実行を開始できるようになり、後続のテストが巻き込まれて失敗することがなくなりました。また、今回我々は実装していませんが、Cucumberにはretryの仕組みがあるので、このエラー処理と組み合わせれば失敗したテストケースのクリーンな状態での再実行も可能になります10。
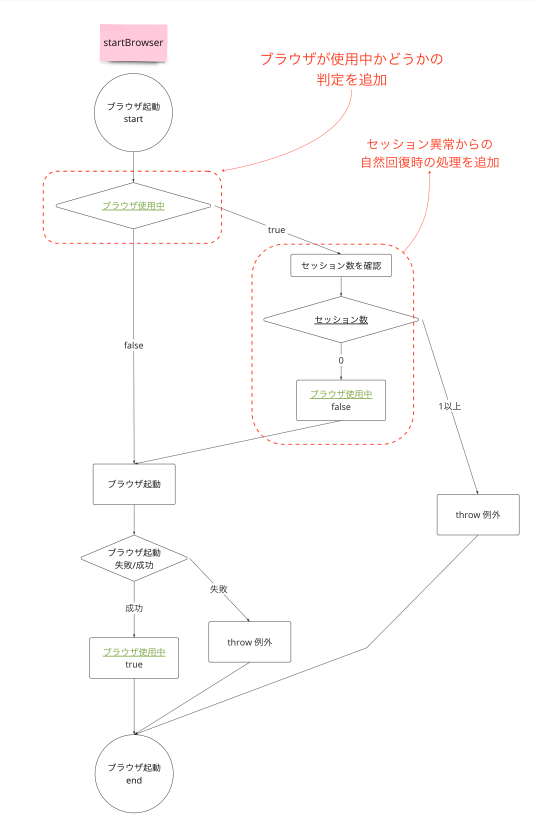
また2つ目の対策として、Resource Poolパターンを参考にしてBrowserのリソースを一箇所で管理するように再設計しました11。修正前はテストケースが並行実行されてしまった際に、Browserが使用中であってもすべてのテストケースが同時にBrowserの使用を試みてしまう作りになっていました。修正後はBrowserの空き状態を管理するようにし、ブラウザがどのテストケースからも使用されていない場合のみテストケースに貸し出されるようにしました。これによりCucumberの問題により万が一テストケースが並行実行されてしまっても、同時に実行されたテストケースでは「Browserが使用中のため失敗したこと」が明確になり、問題の切り分けが楽になりました。
「事象D: Cucumberのstepの60秒タイムアウトエラーで失敗する」の原因と対策
Cucumberのステップの60秒タイムアウトエラーで失敗する原因は、Cucumber⇄Selenium間の通信のタイムアウトが不適切なためでした。分散システムでは複数のシステムが通信しあって連携することで機能を実現しています12。自動テストでも、Cucumber、SeleniumとBrowserは個別のシステムとして動いており、随時通信しあって連携しながらブラウザ操作の自動化を実現しています。お互いのシステムが通信しあえている状況では問題がないのですが、例えば今回の事象のBrowserがハングしてしまったケースのように通信に問題が発生した際には、通信ができるようになるまで待ち続けてしまっていました。
特に今回の事象では、Cucumber側でSeleniumへの通信のタイムアウト(Seleniumのクライアント側のタイムアウト)処理をしておらず、Selenium側から通信が切られるまでのタイムアウト(サーバー側のタイムアウト)の300秒まで待ち続けるようになっていました。そのため、Cucumber⇄Selenium間の通信で問題が発生した際に300秒間待ち続けてしまい、結果として先にCucumberのstepの60秒タイムアウトが発生していました。
対策としてはまずCucumberにSeleniumのクライアント側のタイムアウト処理を追加しました。10秒を閾値とし、ブラウザ操作に閾値以上の時間がかかってしまった場合にはタイムアウトしブラウザーエラーとしてテストケースを失敗させます。また、Seleniumでできるsession-timeoutとsession-request-timeoutなどのタイムアウト値も適切に設定し直しました13。これらの設定値は実験を繰り返しながら決めています。
結果
巻き込まれて多数のテストが失敗することがなくなった
前章での対策の結果、巻き込まれて多数のテストが失敗することがなくなりました。対策前はブラウザがハングした場合に後続のテストケースも巻き込まれて20~70%のテストケースが失敗してしまっていましたが、対策後はこれらの巻き込まれケースがなくなり、ブラウザがハングしたテストケース自身と、実際にテストケースが失敗しているケースのみが失敗するように改善しました。
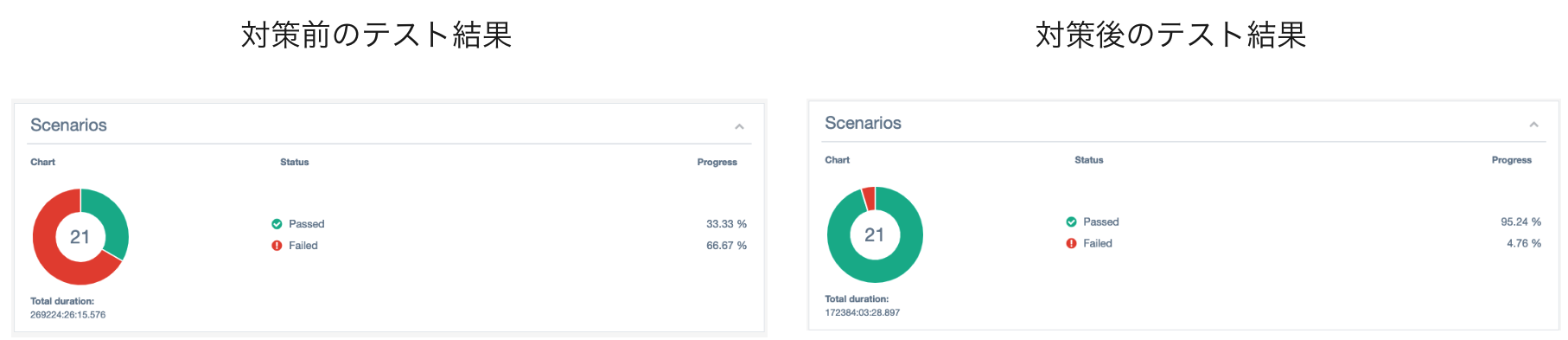
ブラウザがハングしたテストケースでも、そのテストケースの完了処理でブラウザの再起動とセッションのお掃除をすることで、後続のテストケースは巻き込まれることなく成功するようにできました。

ブラウザがハングすることが原因で純粋に失敗しているテストケース割合を対策後に調査したところ、多いときで5%程度でした。他社の事例でも10%程度のFlakyテストは許容していることが多いこと、また、毎回起こるわけではなく4回に1回程度のみの発生頻度で再実行すれば問題ないのでこの事象についてはいったん様子見することにしています。この事象については監視を継続し、発生頻度や発生割合が悪化した際には追加での対策を実施します。
学び: 自動テストシステムに求められる分散システム設計
今回の食べログのSETチームで経験したFlakyテスト通して学んだことを、自動テストシステムに求められる分散システム設計としてまとめます。
自動テストシステムに対する要求
自動テストシステムはテスト手順を自動実行し、その実際結果をあらかじめ定められた期待結果と照らし合わせテストケースの合否を判定するシステムです。そういったシステムの特性上、自動テストシステムは一般的な分散システム設計の中でも以下の品質特性を特に考慮する必要があります。
- スケーラビリティ (テストケースの並列実行の独立性)
- 処理実行の頑健性 (偽陽性とFlakyテスト)
- 可観測性(Flakyテスト原因の可観測性)
スケーラビリティ (テストケースの並列実行の独立性)
自動テストシステムでは大量のテストケースを短時間で実行完了するため、テストケース増加に対しスケーラビリティを確保することが重要です。テストケースを自動実行するために必要なコンポーネント群を並列に並べられるようにすることで、大量のテストを同時に実行できるようになります。ただし、並列に実行されるテストケースやコンポーネントがお互いに干渉しあってしまうと、それが原因でテストケースが意図せず失敗してしまいます。この問題を防ぐためには分散システムの構造をきちんと設計することが必要です。
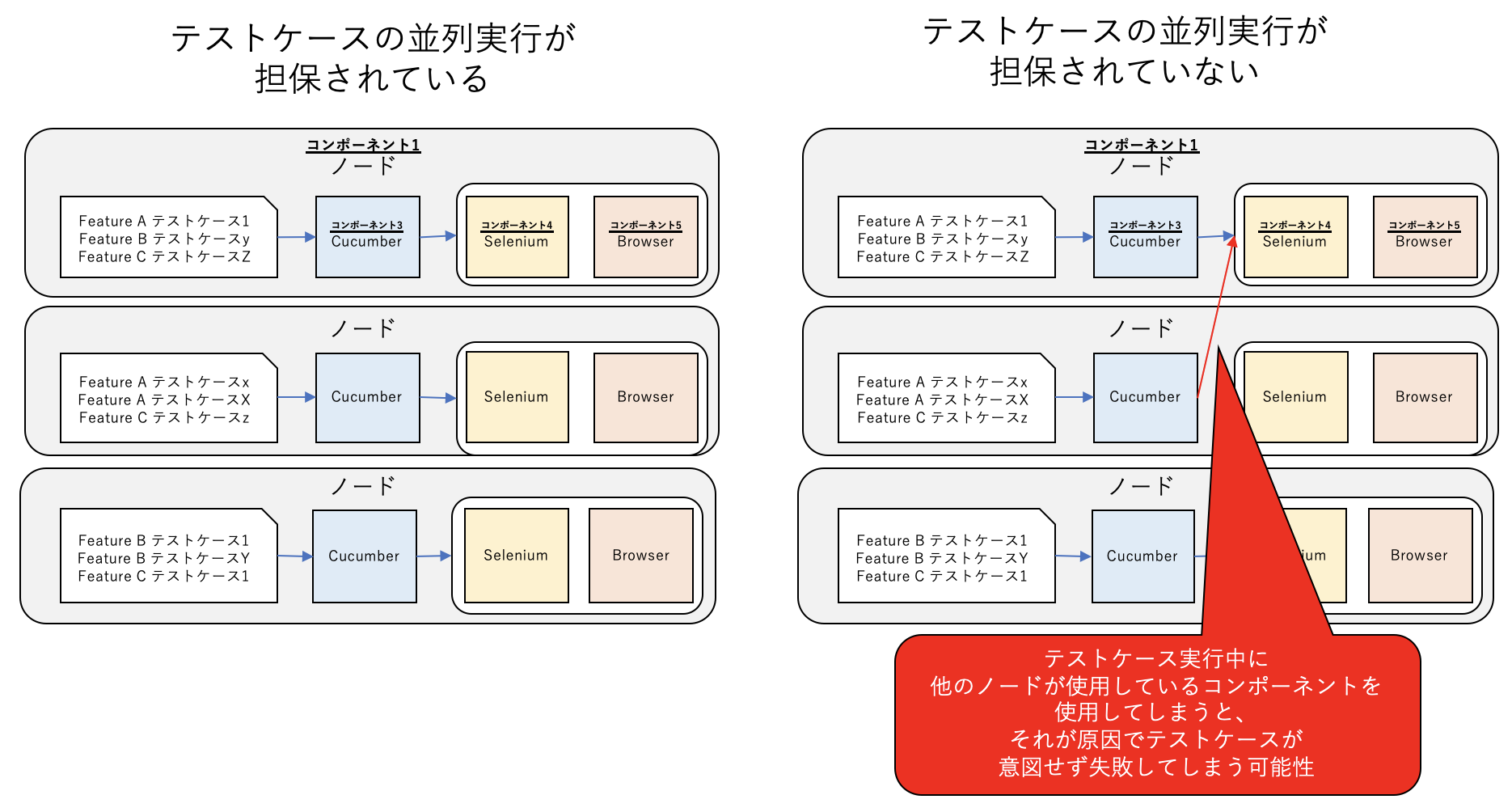
設計上の工夫: 構造の設計
テストケースの並列実行の独立性を確保するためには、テスト実行の際に利用されるリソース (コンポーネント/データ/CPUやメモリなど)について
- 並列実行されるテストケースで共有されるもの
- 並列実行されるテストケースで共有されないもの
を明確にし、構造を適切に設計することが重要です。
テスト実行の際に利用されるリソースが並列実行されるテストケースで共有されてしまっていると、他のテストケースの処理が干渉してきてそれが原因でテストケースが失敗してしまう可能性があります。そのため、食べログではCucumber、Selenium、Browserなどのコンポーネントはテストケースの並列処理ごとに独立したコンポーネントを用意しています。
一方で、すべてのリソースを完全に共有させないようにすると、物理サーバーを何十台と用意する必要が出てくるためそこはトレードオフとなっています。例えばVM上で自動テストを並列処理させると、物理サーバーのCPUやメモリレベルでは並列処理がお互い干渉しあうので、それが原因でブラウザがハングしたりといったことが起きる可能性があります。これはコストとFlakyテスト発生率のトレードオフなので、Flakyテスト発生率が許容範囲内なのであればリソースを共有することをOKとして構いません。ただしその場合は、それが原因で発生するFlakyテストをすぐに調査できるようにしておいた方がのちのちの自動テスト運用が楽になります。
処理実行の頑健性 (偽陽性とFlakyテスト)
自動テストに求められる大切な機能要求は「本当はテストケースが失敗しているのに、テスト成功として判定されてしまう偽陽性を0にすること」です。しかし、Flakyテストが多いと偽陽性を見逃してしまう可能性が上がってしまいます。これらを防ぐため、テストケースの並列処理でノード間のリソースの共有/非共有を構造的に設計したのと同様に、ノード内のリソースの共有/非共有も構造的に設計することで処理実行の頑健性を担保することが重要です。
設計上の工夫①: エラー処理
Cucumberは(食べログの使い方では)テストケースを順次実行するため、複数のテストケースが同時にSeleniumやBrowserのリソースを共有することは通常発生しません。ですが、順次実行されているテストケースは1つのSeleniumやBrowserを使い回しており、これらは1 つのノードで実行されるテストケース間では共有されています。また、前述の食べログのFlakyテストの事例でも触れたように、なにかしらの異常状態が発生した場合には意図せず複数のテストケースが同時にSeleniumやBrowserにアクセスしてしまいます。そのため、テスト実行が成功している際には問題になりにくいですが、共有されているリソースのエラーが適切に処理されていないとそれが原因で後続のテストを巻き込んで失敗してしまうケースが発生してしまいます。
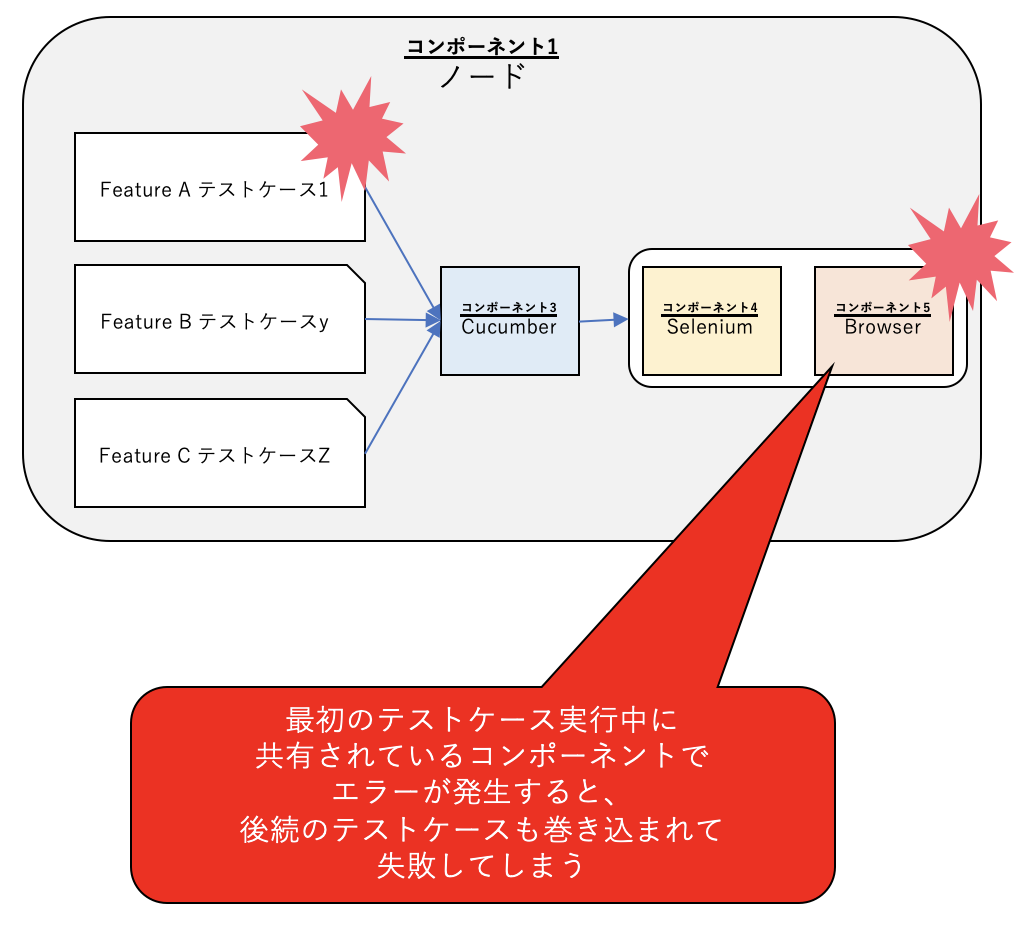
処理失敗時のエラー処理
共有されているコンポーネントでエラーが発生した際のエラー処理を適切に実装します。ポイントは2つあり、1つ目はできるだけ一箇所で処理を実装すること、2つ目は回復処理をできるだけシンプルかつ汎用的にすることです。
1つ目のできるだけ一箇所で処理を実装することは、ソフトウェア異常系の仕様をシンプルにするためです。エラーはプログラム上のいたるところで起きるためそれぞれの箇所でついエラー処理も実装してしまいたくなってしまいますが、そうすると異常系のコードが散らばってしまいわかりにくくなってしまいます。エラーが起きた箇所では例外を投げるだけにし、できるだけ一箇所でエラー処理をした方がプログラムとしてわかりやすくなります。食べログではエラー処理をテスト実行終了後のAfter一箇所に集約していますが、これはBeforeに集約してもよいです。
2つ目の回復処理をできるだけシンプルかつ汎用的にすることは、さまざまな原因で起こりうるエラーに対する処理をそれぞれ用意するのではなく、どんな問題が起きても必ず回復できる方法を少数用意することです。食べログのFlakyテストの事例では、ブラウザがハングした際にはブラウザを再起動しセッションをクリアさえすれば確実に回復できるので、この回復方法のみを実装しています。
コンポーネント間の通信失敗時のエラー処理
分散システムとして実装されているE2E自動テストでは、通常の分散システムと同様にコンポーネント間の通信失敗時のエラー処理を適切に設計しておくことも重要です。分散システムではそれぞれのコンポーネントがクライアント、サーバーとしてお互い通信しあって連携し機能を実現していますが、これらの通信は成功することが100%保証されているわけではなく、しばしば通信は失敗します。この通信失敗のエラー処理を適切に実装していないと、テストケースが意図通りに失敗しているのか、通信の失敗によってFlakyに失敗しているのかがわかりにくくなってしまいます。
Seleniumでは、
- Script timeout (操作スクリプトのタイムアウト)
- Page Load timeout (ページ読み込みのタイムアウト)
- Implicit timeout (要素検索のタイムアウト)
などのページ操作にまつわるタイムアウトを設定します。これらに加えて、コンポーネント間の通信失敗時のタイムアウトとして
- session-timeout (セッションが使用されてない状態が継続された際のサーバー側のタイムアウト)
- session-request-timeout (セッションが張られる前の待機状態のタイムアウト)
を適切に設定することができます。
設計上の工夫②: スレッド処理
食べログでのCucumberの使い方ではテストケースは順次実行されるはずでしたが、意図せず同時に並行実行されてしまっていました。自動テストもソフトウェアであるため異常時にどんな挙動をするかはわかりません。そのため、SeleniumやBrowserなどの共有されるリソースについてはスレッドセーフに実装しておいた方が安全です。ソフトウェア上の共有リソースをスレッドセーフに実装するには、Resource Poolパターンがおすすめです。
可観測性(Flakyテスト原因の可観測性)
ここまで見てきたように、分散システムとして構成されている自動テストで発生するFlakyテストは単純なテスト手順の自動化ミスとして生じるだけでなく、分散システム上で共有されているリソースや連携のエラー処理が原因でも発生します。こういったFlakyテストの発生率を許容範囲内でコントロールし調査や修正にかかるコストを低減していくためには、SREの文脈で議論されることの多い可観測性を自動テストの文脈でも適用していくことが重要です。
設計上の工夫: テストケース失敗と共有リソースのメトリクスの関連付け
Flakyテストの可観測性を実現するためには、まず、Flakyテストに関連するメトリクスを「テストケース失敗」に関連するメトリクスと「共有リソース」に関わるメトリクスに分類し取得します。テストケース失敗に関連するメトリクスは、
- テスト実行ごとのテスト失敗率
- テストケースごとのテスト失敗率
などです。これらを取得するようにすることで、どのテストケースがどういった頻度で失敗するのかが簡単にわかるようになります。
また、テスト実行中の共有リソースに関わるメトリクスには
- ノードのCPU/メモリ/ネットワーク帯域使用率
- 通信のセッション数
- セッションでのエラー発生件数
などがあります。
可観測性を考えるときに重要なことは、テストケース失敗に関連するメトリクスと、これらの共有リソースに関わるメトリクスを関連付けて記録することです。そうすることで、共有リソースが原因で発生するFlakyテストの切り分けが簡単にできるようになります。
また、メトリクスは取得するだけでなく、
- ダッシュボード化し、いつでも誰でも見れるようにすること
- ダッシュボードを見て、Flakyテストの調査や修正を行うプロセスを仕組み化すること
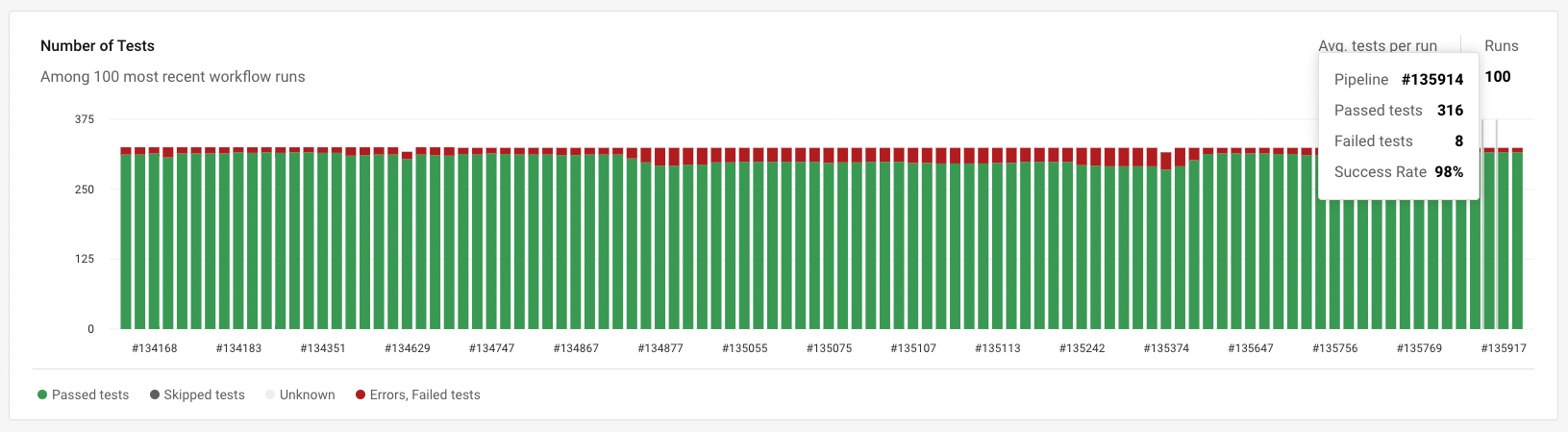
が重要です。食べログではCircleCIのInsightsを使って自動テストに関わるメトリクスをダッシュボード化し、毎朝テスト結果からFlakyテストを確認するプロセスを実施しています。このあたりの取り組みの詳細についてはDevOpsDays Tokyo 2023の発表をご覧ください14。
まとめ
本記事ではE2Eのテスト自動化に求められる設計について、クラウドやコンテナなどのインフラのソフトウェア化技術を使い複数コンポーネントを連携させる分散システム視点で、食べログの事例にもとづいて解説しました。分散システムでは大量のテストケースを並列実行できるというスケーラビリティのメリットがある一方、複数のコンポーネントが連携して機能を構成するため共有リソースやエラー処理の設計について注意が必要です。特に自動テストシステムにおいては、共有リソースやエラー処理の設計の不備が原因でのFlakyテストは単純なテスト失敗に比べて原因調査に時間がかかってしまうことも多く、テスト自動化の天敵となっています。今回の食べログのFlakyテストにもとづく事例が、みなさまのテスト自動化の一助となれば幸いです。
食べログの品質管理室では一緒に働いてくれるエンジニアを大募集しております。是非ご応募お待ちしています。
採用リンク

参考文献
- アジャイル・DevOpsからDeveloper Productivityへ 食べログのDeveloper Productivityチームが目指す姿)↩
- システムテスト自動化 標準ガイド↩
- Advances in Continuous Integration Testing at Google↩
- Introducing BDD↩
- 自動テストのFour Keys ~テストプロセスのソフトウェア化の4つの鍵~↩
- Cucumber Tools & techniques that elevate teams to greatness↩
- Selenium↩
- How we knew it was time to leave the cloud↩
- 世界中のITエンジニアが悩まされている原因不明でテストが失敗する「フレイキーテスト」問題。対策の最新動向をJenkins作者の川口氏が解説 (前編)↩
- Cucumber - Cucumber js - retry↩
- Object Pool Design Pattern↩
- Distributed Computing: Principles and Applications↩
- CLI options in the selenium Grid↩
- 可視化とDevOpsDays Tokyo 2023登壇を通して、自動テストの苦労と楽しさを共有した話↩