こんにちは。食べログでiOSアプリのサービス開発を担当している河崎です。
私の所属するプロダクトチームでは、ユーザーが継続的かつ手軽に行ったお店の記録ができるように、アプリの改善や新機能開発など様々な対応を行っています。
この記事では、iOSアプリで料理写真を判定するために画像分類を取り入れた開発事例の紹介と、開発で得られた知見についてまとめていきます。
目次
画像分類を取り入れた新機能について
まず初めに、食べログアプリで画像分類を組み込んでどのような機能を実装したのかご紹介します。
今回の対応で実現したかった要件は、
「ユーザーがお店で撮った写真をアプリ上に表示し、その写真を手軽に投稿できるようにすること」
です。
食べログアプリには元々、ユーザーが過去に来店した店舗をアプリ内に表示して、食事の記録を促す機能があります。
しかし写真を投稿する場合、ユーザーがカメラロールからお店で撮った写真を選択する必要がありました。
そこで 記録を促す際に「お店で撮った写真」も一緒に表示することで、ユーザーが簡単に写真を投稿できるように対応しました。
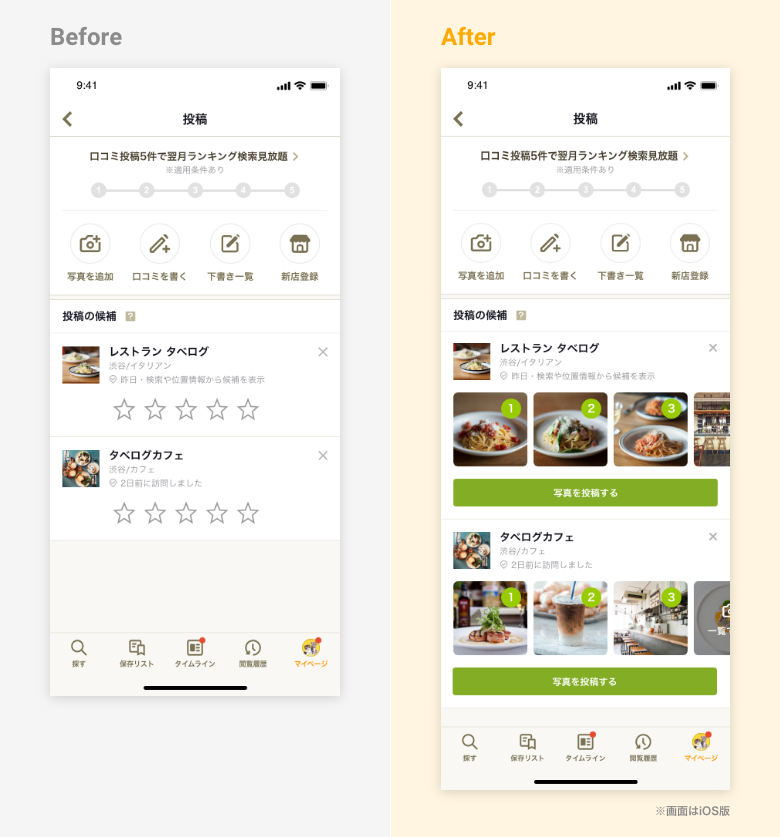
そしてこの機能を開発する上で重要なポイントが、 料理以外の写真は表示から可能な限り除外することでした。
料理と無関係な写真、特に人の写った写真が唐突にアプリ上に表示されてしまうのは、プライバシー観点からも仕様として望ましくありませんでした。
この実現のため、画像分類の機械学習フレームワークの導入を検討し、料理写真の判定を行うことにしました。
本記事ではこの料理写真判定の対応にフォーカスして取り上げていきます。
画像分類の対応方針
画像分類の実現に際して、大きく以下の2つの方針が考えられます。
- 方針1:公開されている画像分類用のモデルやフレームワークを使用する
- 方針2:独自の画像分類用のモデルを構築する
方針1:公開されている画像分類用のモデルやフレームワークを使用する
画像分類用のモデルを自分で構築せず、公開されているモデルやフレームワークを使用して実現する方針です。
例えばiOSでは、Apple標準の VisionフレームワークのAPIを使用する方法が考えられます。
また簡単にアプリに組み込めるCore MLモデルのリストをAppleが公開しており、ダウンロードして使用することもできます。
もし要件にマッチするモデルやフレームワークが見つかれば、導入コストを抑えて簡単に画像分類を行うことができる点が魅力です。
今回はこちらの方針で対応を進めました。
方針2:独自の画像分類用のモデルを構築する
AppleのCreate MLなどを利用してモデルを新規作成、もしくは公開されているモデルに追加学習させることにより、独自のモデルを構築する方針です。
公開されているモデルやフレームワークでは要件にマッチしない場合、この方針で検討する必要があります。
今回の対応では要件にマッチするモデルやフレームワークがあるかを調査しつつ、並行して独自のモデル構築の実現性についても検討を進めました。
幸い弊社内には機械学習分野の専門チームが存在するため、モデル構築の実現性についてヒアリングすることができました。
結論として、モデルの構築は今回の要件に対してコストが高いと判断し、そのまま使えるモデル等が見つからなかった場合の最終手段という位置付けとしました。
コストが高いと判断した理由
コストが高いと判断した理由として、公開されているモデルに追加学習させること自体は難しいわけではなかったものの、モデル構築後も精度監視や再学習などの運用設計が必要となるためです。
- モデルの精度監視:モデルが適切な精度で機能しているかの監視
- モデルの再学習:モデルの精度を維持するための再学習
例えば、スマホで撮影した写真の画質が年々向上していくことで、何かしら精度に影響があるかもしれません。
そういった変化を検知し再学習させる運用設計のコストは大きくなると推測できます。
勿論、精度の変化に関しては公開されているモデル等を使用した場合も同じことが言えますが、配布元によるバージョンアップを望める点が大きな違いといえます。
機械学習モデルの運用については 「MLOps」 と呼ばれるプラクティスがありますので、もしご興味のある方は調べてみることをお勧めします。
アプリ特有の考慮すべき条件
ユーザーが撮った写真を食べログアプリ内で分類するという特性上、アプリ特有の考慮すべき条件がいくつか挙げられます。
- アプリ特有の考慮すべき条件
- オンデバイスであること
- モデルサイズが小さいこと
- 解析速度が速いこと
オンデバイスであること
ここでのオンデバイスであるとは、「インターネットを介さずアプリ内部で処理が完結すること」を指しています。
もし今回の要件でインターネットを介してしまうと、ユーザーが撮った写真をサーバーに送る必要性があり、プライバシー観点で問題が発生する可能性があります。
また大量に写真を送ることはデータ通信量の観点でも問題があります。
アプリ内部で処理が完結すればインターネット接続を必要としないので、このような問題を解消することができます。
モデルサイズが小さいこと
オンデバイスで画像分類を実現する方法として、アプリ内に画像分類用のモデルを組み込んで使用する方法が考えられます。
画像分類用のモデルはMobileNet、Resnet50、SqueezeNetなどいくつか選択肢がありますが、
これらをアプリ内で保持する場合、アプリ容量の増加に直結します。
そのため導入によりどの程度アプリ容量が増加するかを把握して、許容できるモデルを選択する必要があります。
その際、モデルサイズが小さい分、分類精度が低くなるということも考えられるため、そのモデルが求める精度に達しているかも検証しておくと安心です。
解析速度が速いこと
写真解析に長時間かかりユーザーを待たせてしまっては本末転倒のため、解析速度も事前に把握しておきたい項目です。
また今回の検証の中で、解析速度は写真によってばらつきがあることもわかったため、長時間の解析も想定したアプリUIの工夫も考慮しておきたい点です。
Visionフレームワークでの実現
ここからは具体的な実現方法や知見について記載します。
今回の対応ではVisionフレームワークのVNClassifyImageRequestを用いて機能実装を行ったため、その点を中心に記載していきます。
記事の後半ではそれ以外の方法としてどういった選択肢があるか簡単に触れたいと思います。
VNClassifyImageRequest とは
Apple標準フレームワークのVisionでは、画像の分類やオブジェクト検出で使用できる様々なAPIが用意されています。
今回はそのAPIの一つであるVNClassifyImageRequestを使用しました。
このAPIは名前の通り、画像分類を行うためのAPIです。
画像分類モデルのMobileNetと同等の機能を提供しており、
アプリサイズを増やすことなく画像分類を実現できることがメリットとして記載されています。
■引用:[Classifying Images with Vision and Core ML]より抜粋
Before you integrate a third-party model to solve a problem — which may increase the size of your app — consider using an API in the SDK. For example, the Vision framework’s VNClassifyImageRequest class offers the same functionality as MobileNet, but with potentially better performance and without increasing the size of your app.
本APIについては、WWDC2019の「Understanding Images in Vision Framework」でも触れられているため、興味のある方はぜひご覧ください。
VNClassifyImageRequest の使い方
VNClassifyImageRequestは、以下のサンプルコードのように簡単に使用することができます。
let handler = VNImageRequestHandler(cgImage: cgImage,
options: [:])
let request = VNClassifyImageRequest()
try? handler.perform([request])
let observations = request.results as? [VNClassificationObservation]
最後の行では、VNClassificationObservationの配列を受け取っています。
VNClassificationObservationは以下の値を持っています。
- identifier(識別子): String型
- 例:food, people, outdoor, sky
- confidence(確度): VNConfidence型(Float型のtypealias)
- 0.0 ~ 1.0の値
confidenceの高いidentifierは、その写真を適切に表している可能性が高いということになります。
逆にconfidenceが低ければ、その写真を表すidentifierである可能性が低いと判断できます。
例としてこちらの写真を解析してみます。

結果はこのようになりました。
(food, 0.9052735), (spaghetti, 0.90527344), (tableware, 0.68762106), (utensil, 0.68762106), (fork, 0.6791992), (wood_processed, 0.42041016), (structure, 0.4204101), (plate, 0.34179688), (tool, 0.13696405), (knife, 0.13696289), ...以下続く
ここではfood, spaghettiが0.9以上という高いconfidenceとなっており、この写真のidentifierとして正しい可能性が高いと推測できます。
本APIがどのようなidentifierに対応しているかは、supportedIdentifiersを呼び出すことで確認できます。
このように一つのデータに対して複数のラベル付を行うことは、機械学習の用語では多ラベル分類と呼ばれます。
よってVNClassifyImageRequestは多ラベル分類を行うAPIであると言うことができます。
料理判定の実現方法
VNClassifyImageRequestを用いて、今回の要件の実現方法を考えていきたいと思います。
まず今回実現したい画像分類の機能要件を改めて整理してみます。
- 機能要件
- 料理写真を判別できること
- 人が写っている写真を判別し、除外できること
- 料理と人が両方写っている場合も除外する
そこで料理と人を表すidentifierが存在するか調べたところ、以下のidentifierが見つかりました。
- food
- people
これらを利用することで、例えば、
- foodのconfidenceが0.9以上の場合は、料理の可能性が高いと判断し抽出
- peopleのconfidenceが0.1以上の場合は、人が写っている可能性があると判断し除外
とすれば、料理の可能性が高い写真を抽出し、さらに人が含まれる可能性のある写真を除外することができます。
ここでは仮の閾値を設定しましたが、実際にconfidenceの閾値をいくつに設定するかは、要件に合うように動作検証しながら調整する必要があります。
またこれらのidentifierが将来的にサポート対象外になる可能性もゼロではないため、前述のsupportedIdentifiersに使用するidentifierが含まれているか、実装時の使用箇所でチェックしておくとより安心感があります。
問題点
画像分類全般で言えることですが、全てのデータが正しく分類されることはなく、誤った分類がされることもあります。
ここでは、本APIの検証をしている中で問題になったケースをいくつかご紹介します。
(1)confidenceが低くても正しいケースは多くある
confidenceの値が0.0に近い値でも、そのidentifierに分類されるケースが多く発生していました。
特に料理写真の分類で顕著に発生し、foodが0.1未満と低い値でも料理写真であるケースが多くありました。
しかし判定の閾値を下げると誤った分類が増えてしまうリスクもあります。
今回は低い値の料理写真が除外されてしまう点は許容とし、チームの企画メンバーと相談しながら最終的な閾値を決めていきました。
(2)人の腕や手、脚が写っていると人判定される
人の顔は写っておらず、人の身体の一部分(腕、手、脚など)が写っているだけでも、人判定されて表示から除外されてしまう現象が発生しました。
人の分類として間違ってはいませんが、要件的にはできれば表示から除外したくないという意見もありました。
これは特にpeopleのconfidenceの閾値を低めに設定したときに発生頻度が高まりました。
しかしconfidenceの閾値を上げると、今度は本来除外すべき人の写真が表示されてしまうリスクもあります。
人の写真については出来る限り除外する必要があるため、このケースの発生は許容とし、人と判定するconfidenceの閾値は低めの値で調整しました。
なお本筋から逸れるため詳細は割愛しますが、人の顔だけを判定したい場合、同じVisionフレームワークのAPIである VNDetectFaceRectanglesRequestを使用する方法も考えられます。
(3)お店のメニュー表が料理判定される
お店のメニュー表の料理画像を料理判定してしまうケースが多くありました。
food以外のidentifierもチェックすれば、もしかするとメニュー表かどうか見分ける方法もあるかもしれませんが、特に要件として表示されても問題ないため許容としました。
(4)解析速度にばらつきがある
写真1枚あたりの解析速度は0.01秒から1秒を超えるものまで、大きくばらつきがありました。
今回の要件ではリアルタイムで解析した結果をユーザーに表示することと、解析する写真の枚数が多くなることも予測されたため、解析に長時間かかる最悪のパターンも想定しておく必要がありました。
対策として写真解析の合計時間にリミットを設け、一定時間経った場合は解析を終了するようにしました。
その他の画像分類の実現方法
今回は採用に至らなかったその他の画像分類の実現方法についても、いくつか簡単にご紹介したいと思います。
Visionフレームワーク + Core ML(Apple)
もし前述した Core MLモデルのリストに使用したいモデルがある場合や、モデルを自前で構築する必要がある場合は、Visionフレームワークと一緒にCore MLを使用する方法が有効です。
実装方法についてはAppleがサンプルコードを提供しており、VNCoreMLRequestを使用して簡単に実装できることがわかります。
モデルを新規構築する必要がある場合はCreate MLを使用することもできます。
その他、今回詳細な調査は行っていませんが、他社製のツールで構築したモデルをCore MLに変換する方法も用意されているようです。
詳細についてはトレーニング済みモデルのCore MLへの変換をご参照ください。
なお今回の料理判定の実装に関しては、Core MLモデルのリストに公開されているモデルでは要件を満たすことができませんでした。
現在Appleが公開している画像分類用のCore MLモデルとして MobileNetV2、Resnet50、SqueezeNetがありますが、いずれも「food」のような料理を表す識別子ではなく、料理の固有名詞(例:pizza、carbonara)で分類されてしまいました。
今回は料理名を判定したいわけではなく、料理かどうかを判定したかったため使用を見送りました。
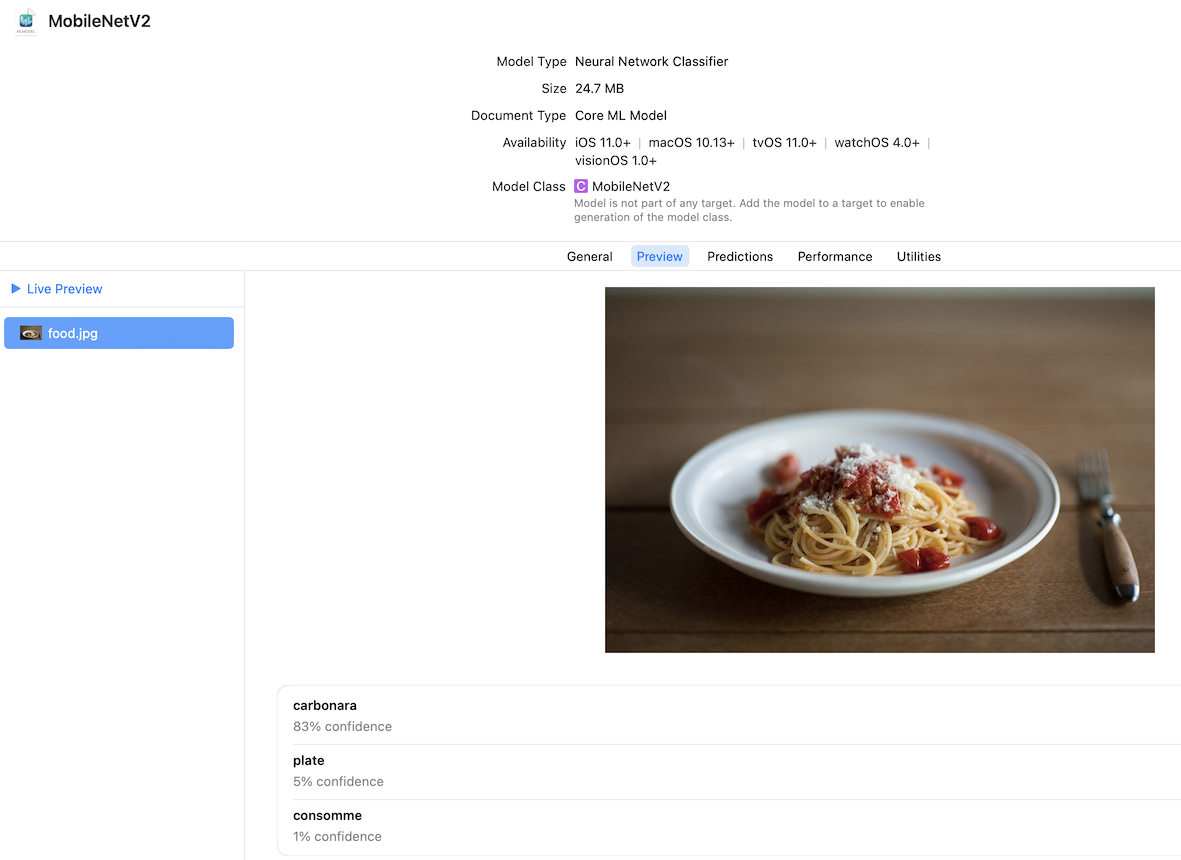
補足として、Core MLを使用して写真がどのように分類されるかは、実装なしでXcodeから確認することができましたのでご紹介します。
- 確認したいCore MLモデルをダウンロードしてXcode上に配置、選択します
- モデルの情報がXcode上に表示されるので、そこでPreviewをクリックします
- 任意の写真をドラッグ&ドロップすることで、その写真の分類結果を表示することができます
ML Kit(Google)
ML KitはGoogleが提供するモバイル向けの機械学習フレームワークで、画像ラベル付けAPIが公開されています。
このAPIを使用することで画像分類を行うことができ、カスタマイズ不要のデフォルトのモデルでも400以上の識別子に対応していました。
対応しているラベルの一覧を見ると以下のように「料理」という識別子も見つかっており、実際に料理かどうかの判定も行うことができました。
■引用:[ML Kitの画像ラベル付け:デフォルトモデルのラベル]より抜粋
116 カーリング
117 料理
118 ネコ
119 ジュース
しかし今回はVisionフレームワークで事足りたこと、また検討時点でXCFrameworkへの対応が確認できなかった点など開発環境の運用面から判断し、導入を見送りました。
TensorFlow Lite(Google)
TensorFlowとはGoogleが開発したオープンソースの機械学習フレームワークで、モバイル向けに提供されているのがTensorFlow Liteです。
こちらについては特に詳細な検証を行わなかったため名前の紹介に留めますが、事前トレーニング済みモデルが提供されているため試してみても良いかもしれません。
※本記事執筆時点でTensorFlow LiteはGoogle AI Edgeの一部となったとアナウンスがありました。最新情報は公式HPをご確認ください。
まとめ
最後に、今回の記事のポイントをまとめて終わりにしたいと思います。
- iOSではVisionフレームワークやCore MLを活用することで、簡単に機械学習を導入することができます
- 今回使用した
VNClassifyImageRequestは多ラベル分類を行うAPIで、アプリサイズを増やすことなく画像分類を実現できます
- 今回使用した
- アプリに機械学習を導入する際は、オンデバイスでの実現を検討してみましょう
- 対象データの送信が不要になり、プライバシー懸念解消等のメリットが期待できます
- 写真分類の解析速度や精度、導入によるアプリサイズ増加量をチェックしておきましょう
- 仮にどんなに精度が高いモデルでも、サイズが大きすぎるとアプリに組み込むのが難しくなります
- 誤った写真分類が行われる可能性や、解析に長時間かかる可能性も考慮して要件定義、設計を行いましょう
- 全てのデータが正しく分類されることはなく、解析時間にもばらつきがあります
- もし独自の画像分類用のモデルを構築する場合、モデルの精度を維持するための運用設計コストも考慮しましょう
- 精度の変化を検知し、再学習させる仕組みが必要になります
食べログiOSアプリ開発にご興味を持っていただけた方は是非下記の採用情報ページもご覧ください。
カジュアル面談も大歓迎ですので、ご希望の方はフリーテキストに、「カジュアル面談希望」と記載ください。
