はじめに:iOSDC2025でのデモアプリについて
こんにちは。食べログカンパニー 開発本部 国内メディア開発部の筒井です。普段は食べログiOSアプリの開発を行なっております。
食べログは、2025年9月19日〜21日に開催されたiOSエンジニアの祭典「iOSDC Japan 2025」に、本年度もスポンサーとして参加しました。(当日の様子はこちら)
今年の食べログスポンサーブースでは来場いただいた方に楽しんでいただけるよう「オンデバイスAIによる口コミ生成」をコンセプトとしたデモアプリを展示しました。
数百名の方がブースを訪れてくださり、実際にちょうど100件ほど口コミを生成していただきました。
本記事ではこのデモアプリを作成する過程や生成した結果から得られたオンデバイスAI活用における課題と可能性についてお話しできればと思います。
より使いやすい食べログアプリを目指して
近年はAIの目覚ましい成長により、サービス内でAIを利用したソリューションを提供することが当たり前になってきました。食べログでもAIによる翻訳を行うなどAIを活用したサービス提供を行なっていますが、口コミや店舗情報など非常に多くの情報を扱い、提示しているためAIを活用する余地はまだまだありそうです。
また、食べログiOSアプリには口コミ投稿やお店探しなど場所を選ばず高頻度で利用される機能が多く存在します。より便利にアプリを利用していただくための技術的な検証を目的として、通信状況に依らず高速で動作するオンデバイスAIに着目し、デモアプリを作成することにしました。
デモアプリの概要
検索やレコメンド等お店を探すこと自体にもAIが活用できる要素は多く存在しましたが、楽しく体験できるデモアプリというテーマも考慮して口コミを生成するアプリケーションを作成しました。 なお、このアプリケーションで実装した機能をそのままサービスインする予定はありません。
デモアプリは以下のステップで口コミを生成します。
- スタイル(口調・文体)を選択
- 店舗を選択し、メニューへの評価+感想を入力
- 口コミ生成
スタイルは幅広く"宇宙人"や"武士"などのキャラクターを与えるものや、"関西弁"など口調を指定するものを用意しました。
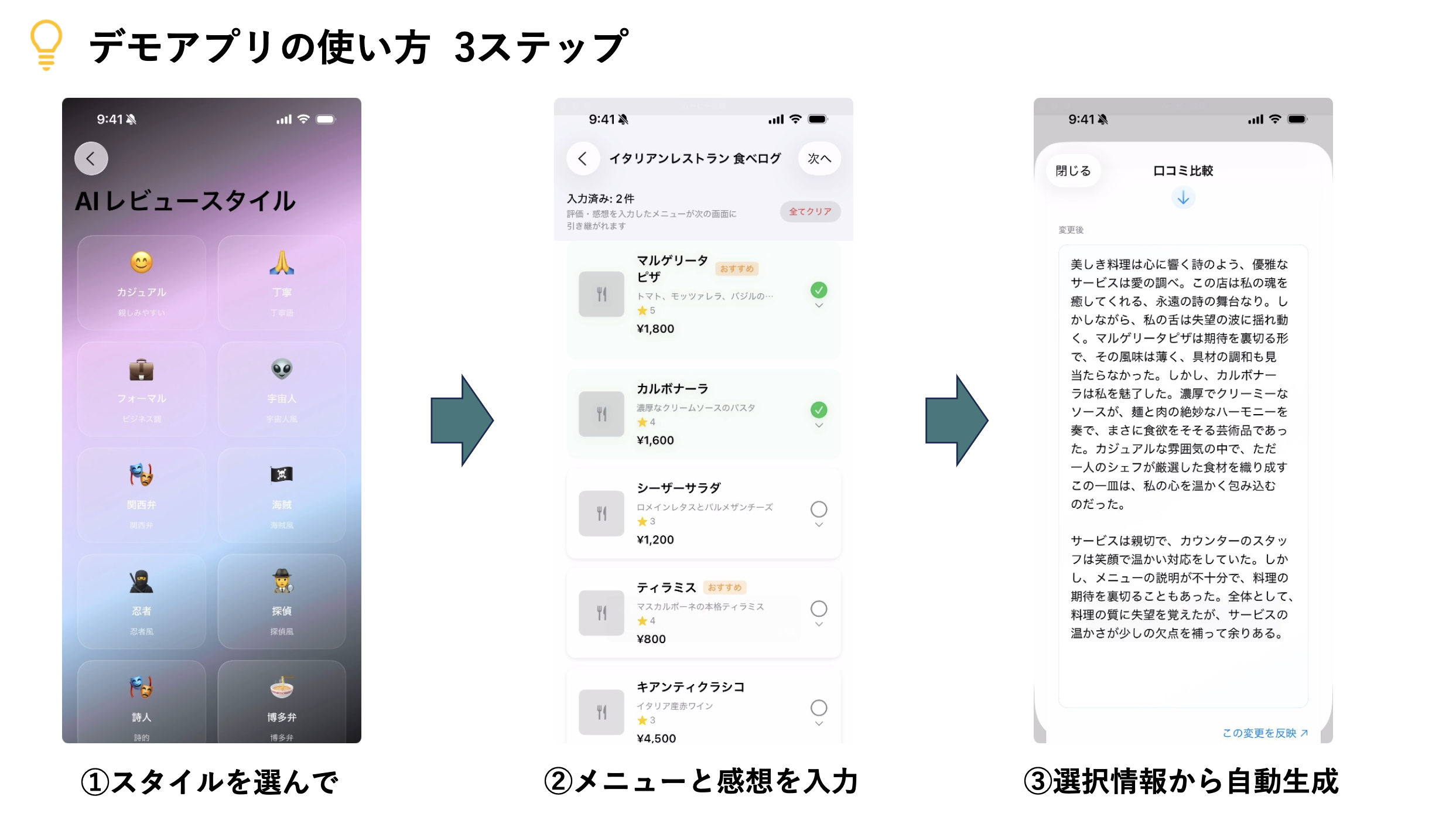
また、最も重要になる口コミ生成機能にはWWDC25にて紹介された Foundation Modelsフレームワークを利用しました。
Foundation Models フレームワークについて
Foundation ModelsフレームワークはiOS26より提供される、端末に搭載されたAppleIntelligence(AIシステム)をアプリケーションから利用するためのフレームワークです。
「数行で容易に実装が可能」という売り文句で実装コストも低いことが予想され、AppleIntelligenceに対応した端末があれば誰でも利用可能であるためプロダクトへの導入も現実的に検討できます。
AIによるユーザビリティの向上を目指す上で実際にサービスで利用できる性能なのか、触れ込み通り簡単に実装できるのかなど、最新技術に対する知見を貯めるために今回こちらを利用しました。
Foundation Models を利用した実装
実装はAIコーディングツールであるCursorを利用しました。
実装時はWWDC25でFoundation Modelsフレームワークが発表された直後でありCursorから利用可能なモデルはフレームワークの利用方法を学習していなかったため、事前に利用方法をまとめたドキュメントを作成しコンテキストとして与えることでほぼ100%のコードをCursorで生成しています。
今回のアプリでは店舗情報、メニューの評価情報、スタイルを受け取り、口コミ本文・サービスへの評価・味への評価・総合評価を出力しています。
※店舗情報やメニューはすべて架空の情報です。
一部省略・変更を加えていますが、口コミを生成するコードは大まかに以下のような実装です。
参考例からも分かる通り、非常にシンプルな実装で生成機能を実装できました。
/// 店舗情報とメニュー情報をプロンプトに埋め込めるテキストへ変換 func buildContextText(from input: ReviewGenerationInput) -> String { var contextParts: [String] = [] // 店舗情報 if let restaurant = input.restaurant { contextParts.append("Restaurant: \(restaurant.name)") if let description = restaurant.description { contextParts.append("Description: \(description)") } contextParts.append("") } // メニュー評価 if !input.menuImpressions.isEmpty { contextParts.append("Menu experiences:") for impression in input.menuImpressions { contextParts.append("Menu: \(impression.menu.name)") contextParts.append("Personal rating: ⭐️\(impression.rating)") contextParts.append("Experience: \(impression.impressionText)") contextParts.append("") } } return contextParts.joined(separator: "\n") } /// 生成時のプロンプト func createDetailedReviewGenerationPrompt(from input: ReviewGenerationInput) -> String { let contextText = buildContextText(from: input) return """ Create a restaurant review based on the following information: \(contextText) Generate a comprehensive review that reflects these experiences and restaurant details. """ }
/// 出力されるモデル @Generable private struct AppleIntelligenceReviewModel { @Guide(description: "Detailed review content without score info. more than 200 characters.") var content: String @Guide(description: "Service quality rating score (evaluated on a scale of 0-5)") var serviceScore: Int @Guide(description: "Food taste rating score (evaluated on a scale of 0-5)") var tasteScore: Int @Guide(description: "Overall rating score (evaluated on a scale of 0-5)") var overallScore: Int }
/// review生成 func generateReview(from input: ReviewGenerationInput) async throws -> AppleIntelligenceReviewModel { // Apple Intelligence利用可能性の確認 try checkAppleIntelligenceAvailability() // セッションの初期化(スタイルに応じたInstructionsを持つSessionを生成) let session = createSession(for: .review(style: input.reviewStyle)) // ReviewGenerationInputから詳細なプロンプトを生成 let prompt = createDetailedReviewGenerationPrompt(from: input) do { let response = try await session.respond(to: prompt, generating: AppleIntelligenceReviewModel.self) return response.content } catch { // 適切なエラーをthrow } }
実装に際して、いくつかLLM特有のエラーハンドリングに気をつける必要があります。
① ContextWindowの超過
1度の入力でContextWindowを超過するような場合は一度サマリーを作成して入力を小さくするなどの工夫が必要です。 サマリーを扱った生成でもエラーをハンドリングする必要があるため、どこまで入力を保証するかも検討する必要があります。
func generateReview(from input: ReviewGenerationInput) async throws -> GeneratedReview { do { // 生成処理 } catch LanguageModelSession.GenerationError.exceededContextWindowSize { let newSession = createSession(for: .review(style: reviewStyle)) // コンテキストサイズ超過時は要約版で再試行 let summarizedPrompt = createSummarizedReviewGenerationPrompt(from: input, style: reviewStyle) // 要約版プロンプトで再生成(ここでもエラーはthrowされる) let newResponse = try await newSession.respond(to: summarizedPrompt, generating: AppleIntelligenceReviewModel.self) return newResponse.content } catch { // ハンドリング } }
②利用権限の確認について
AppleIntelligenceの利用権限ON/OFFだけでなく、「モデルをセットアップ中」など端末の状態によっても利用可能かが判定されます。 モデルアップデートなど定期的に実施されるため、ユーザーが意図的に操作していなくても一時的に利用不可の状態になり得ます。利用時は必ず適切なエラーハンドリングを行いましょう。(参考)
③振る舞いを定義するプロンプトの実装について
選択したスタイルに応じた口コミを生成するため、Session生成時のInstructionsにスタイルの情報を埋め込んでいます。
一般的なLLMと同様、日本語ではなく英語で指示し、例文を与えることでより自然な文章を生成できる傾向がありました。
特別な理由がない場合は英語で指示するとよさそうです。
/// Instruction生成 func createInstructions(for style: SessionType) -> String { switch type { case .review(let style): let description = styleDescription(for: style) // 例: "The sustenance on this planet exceeded our expectations in palatability." let exampleText = styleExampleText(for: style) return """ You are a professional restaurant reviewer who writes as \(description). Generate authentic Japanese restaurant reviews using this exact tone: \(exampleText) Rules: - Always respond in Japanese language - Match the exact tone and expressions shown above - MUST use similar vocabulary and phrases from the example text above - Incorporate the style-specific expressions and word choices from the sample - Write detailed, specific content (200+ characters) - Focus on experiences, not scores in content """ case .... } }
FoundationModelsを利用して分かった課題と可能性
オンデバイスAIの「適材適所」を見極める重要性
実際の生成結果を確認すると以下のような問題のある口コミが生成されていました。
①日本語と英語が入り混じった表現になる
「非常にdeliciousでした」といったように、英語と日本語が混在する出力が時折ありました。プロンプトを全て日本語にした場合も同様であり、指示による問題ではなさそうです。
②入力として与えていない要素に関して評価を生成してしまう
サービスへの言及はないのに食事の評価を参照して「サービスも完璧だった」などの文章を生成しているケースがありました。
これは出力する文字列を200文字以上と指定していたため、話を膨らませようとサービス等入力されていない項目に対する感想を生成してしまった可能性があります。
上記のケースからも分かる通り、一般的なLLMと比較しても端末で動作する分高度な推論を苦手とする傾向があります。
一方で、文章を作成する上での補助的なツールや十分な入力内容をサマリーする機能としての有用性は非常に高いです。 イベントを通して、200字以上の本文+評価を生成するための時間は概ね1~2秒ほどでした。当然ながら人間よりも文章を書くスピードは早く、ユーザーの手間を削減する点では効果的です。また、入力外の項目を生成するという点に関しても入力観点の提案をしてくれると考えると効果的に利用できそうです。
本アプリの出力を確認する限り、正確性の課題をある程度許容できるケースでは非常に有用だと考えます。現時点ではスピード感や操作の簡略化など+αの要素で利用するのが効果的そうです。
また、出力結果のブレをどれだけ許容できるか、問題が発生してもユーザーがその問題に気づきやすいようなフローになっているかといった、問題発生時の対応を十分整備しておく必要があると感じました。
プロンプト調整による制御の難しさ
今回イベントブースで生成された100件の出力について、後日文章として破綻があるか以下の観点で確認したところ、問題がある口コミは23件ほど見受けられました。
- 文章の一貫性("美味しい"といった後"美味しくなかった"という等、文章に矛盾がないか)
- キャラクターの一貫性(途中で口調が変わるなどがないか)
- 評価と文章の一致("非常に美味しい"と記載しているが評価が低いなどの矛盾がないか)
- 入力された情報に関する言及に漏れがないか
- 文章が一般的な日本語として破綻していないか
決して少なくない数ですが、口調や文体を指定したことによる問題がほとんどであり、"カジュアルな文体"といった一般的な概念に基づいて生成される文章に関しては、英語が混じってしまう問題以外発生していませんでした。また、入力した項目が言及されないケースはなかったため、サマリーなど単純な文章生成では問題なく利用可能だと言えます。
一方、口調の指定という観点では明確に語彙や文章の特徴を言語化できるもの(宇宙人、忍者など)は文章に一貫性があり、方言など日本固有の語彙を利用するものは途中でキャラクターが抜けてしまう傾向がありました。日本固有の口調でも、武士や忍者といった広く知られた概念は安定した結果が出力されたため、モデルの学習上の問題の可能性もあります。
今回選択した口調での文章生成では例文を与えましたが、例文への依存は強く、いずれのキャラクターも語彙に柔軟性はありませんでした(古風な言い回しに変更する、例文にない方言を使うなど)。また、例文に「美味しい」という文章を入れていたことで評価が低くても「美味しい」といってしまうケースが多発しました。
デモアプリ作成にあたって、なるべく出力にブレがないようプロンプト等を調整しましたが結果は上記の通り。仕様上の問題も多かったですが、完璧にはなりませんでした。
出力精度の向上に向けて "例文は網羅的に与え、キャラクターを与える場合は具体的に定義する" といった小手先の工夫は可能ですが、キャラクターを与えるなど特殊なユースケースの場合はどこまで突き詰めても100%の精度を実現することは難しそうです。
出力結果が利用するまで分からない以上、想定外の出力を許容できるようなサービス設計が求められると考えます。
デモアプリ開発を通じて
今回はiOSDC2025で展示したデモアプリの開発を通じて、FoundationModelsフレームワークを利用したオンデバイスAIの実装方法と、実際に100件の生成結果から得られた知見について紹介しました。
実装面では、FoundationModelsフレームワークは非常にシンプルなコードで動作し、導入の障壁は低いことが確認できました。一方で、生成結果のブレを完全に制御することは難しく、機能導入を検討するにあたっては想定外の出力を許容できるようなサービス設計が必要であることが分かりました。
オンデバイスAIの活用における可能性
検証を通じて、以下のような活用の可能性が見えてきました。
文章作成の補助ツールとしての活用
短時間(1~2秒程度)で口コミのようなテーマに基づいたまとまった情報を出力できる能力は、ユーザーの入力負担を大幅に軽減できます。完璧な出力を期待するのではなく、ユーザーが編集・調整する前提での下書き生成として捉えることで、実用性が高まります。
アイデア提案機能としての可能性
入力として与えていない要素を生成してしまうという「問題」も、見方を変えればアイデア提案として活用できます。ユーザーが気づかなかった観点を提示することで、より充実した内容作成を支援できる可能性があります。
適用シーンの見極めとUI/UX設計の重要性
ミスが発生しても影響範囲が限定的な機能や、ユーザーによる確認・修正が容易な機能であれば、プロダクション環境でも十分活用できると考えます。特に重要なのは、AI生成であることをユーザーに明示し、出力のブレや誤りを許容できるようなUI/UX設計です。例えば、「AIによる提案」として生成結果を提示し、ユーザーが最終的に確認・編集するフローを組み込むことで、技術的な制約を受け入れつつ利便性を提供できます。このようなUI/UX側での工夫により、利用できるシーンは大きく広がっていくでしょう。
プロンプト設計における学び
100件の生成結果からは、プロンプト設計に関する具体的な知見も得られました。例文を与える場合は網羅的に用意すること、キャラクターを与える場合はその定義を具体的にすることが出力品質の向上に繋がります。ただし、それでも完璧な制御は難しいため、出力結果の確認・修正プロセスを組み込んだサービス設計が求められます。
今後の展望
オンデバイスAI技術は、通信状況に依らず高速で動作するという特性から、口コミ投稿やお店探しなど場所を選ばず利用される機能との相性が良いと考えています。モデルの性能向上に伴い、より複雑な処理も可能になっていくでしょう。
今回の検証で得られた知見を活かし、ユーザー体験を向上させる手段として、今後もサービス内でのAI/LLM技術の活用を検討していきます。 そんな食べログにご興味を持っていただけた方は、ぜひ下記の採用情報ページもチェックしてみてください!カジュアル面談も大歓迎です。
